
Um dos principais problemas que vemos nas empresas que chegam até nós é que suas arquiteturas de dados foram implementadas sem a devida validação de cenários.
Em muitos casos, essas decisões são influenciadas por hype de mercado: uma tecnologia funciona bem para uma empresa com 5 mil ou 10 mil funcionários, e automaticamente assume-se que ela também funcionará em qualquer outro contexto.
Por mais que uma arquitetura esteja validada no mercado, não existe uma solução única que atenda a todos os cenários. Cada empresa possui suas próprias necessidades, volume de dados, maturidade técnica e objetivos de negócio.
E sempre faça as suas POC para testar vários cenários diferentes.
Exemplo pensando num cliente que já tem o seu DW e deseja evoluir a sua Stack, temos algumas opções:
- Evoluir o DW para uma Stack Moderna mantendo o Postgres como camada analitica.
- Migrar essa estrutura para AWS.
- Migrar essa mesma estrutura para Google Cloud.
E agora temos duas opções ou ir pelo feeling, pela experiência, ou deixar os dados responderem.
Que tal implementar o mesmo pipeline de dados nos três cenários informados acima.
Dessa forma iremos conseguir validar alguns tópicos importantes.
- Performance.
- Custo.
- Velocidade de processamento.
- Complexidade de implementação e manutenção.
Então iremos fazer a ingestão dos dados em 3 saídas: Postgres, S3, Google Cloud Storage.
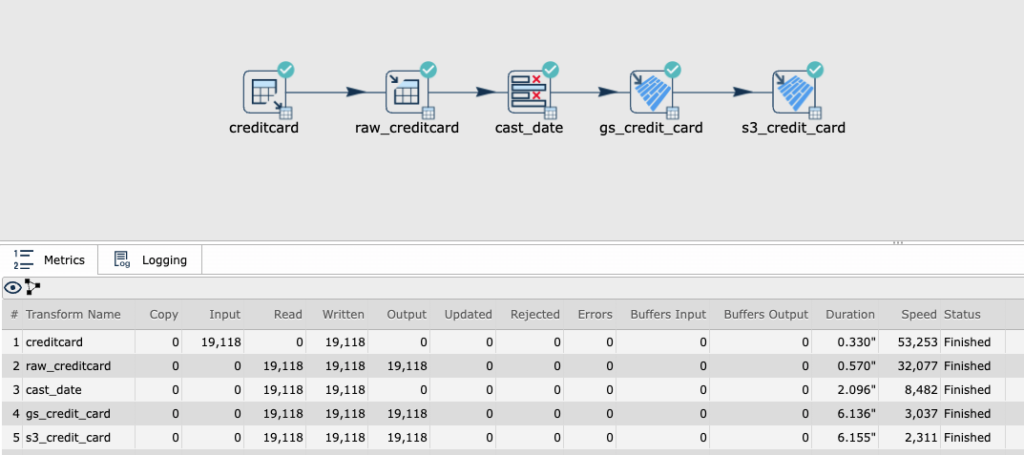
E agora podemos utilizar o dbt para validar esses dados da camada bronze, e gerar os dados na camada silver e gold.
Exemplo do código para gerar a dim_credit_card de forma incremental.
{{ config(
materialized='incremental',
unique_key='creditcardid'
) }}
select
s.creditcardid,
s.cardtype,
s.cardnumber,
s.expmonth,
s.expyear,
s.modifieddate
from {{ ref('stg_credit_card') }} s
{% if is_incremental() %}
where s.modifieddate > (
select coalesce(max(modifieddate), timestamp('1900-01-01'))
from {{ this }}
)
{% endif %}
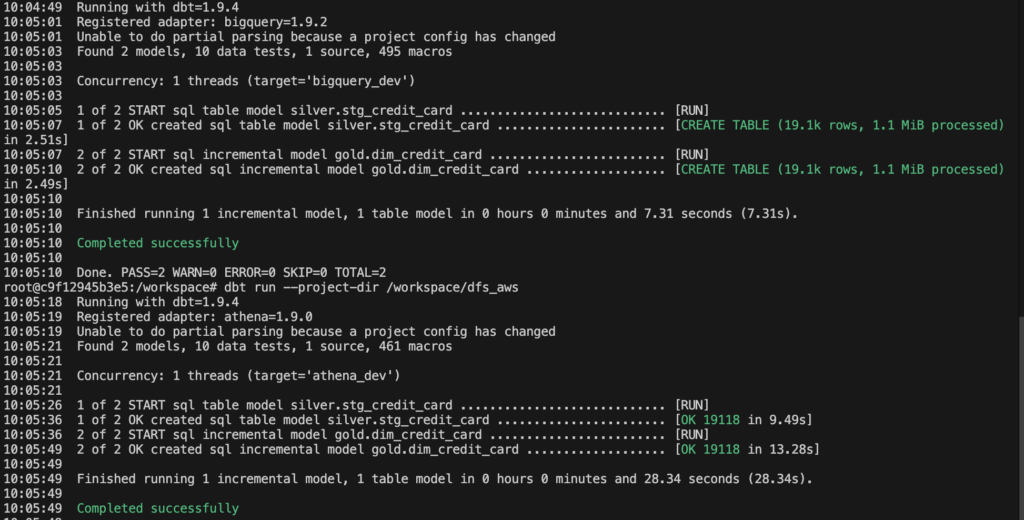
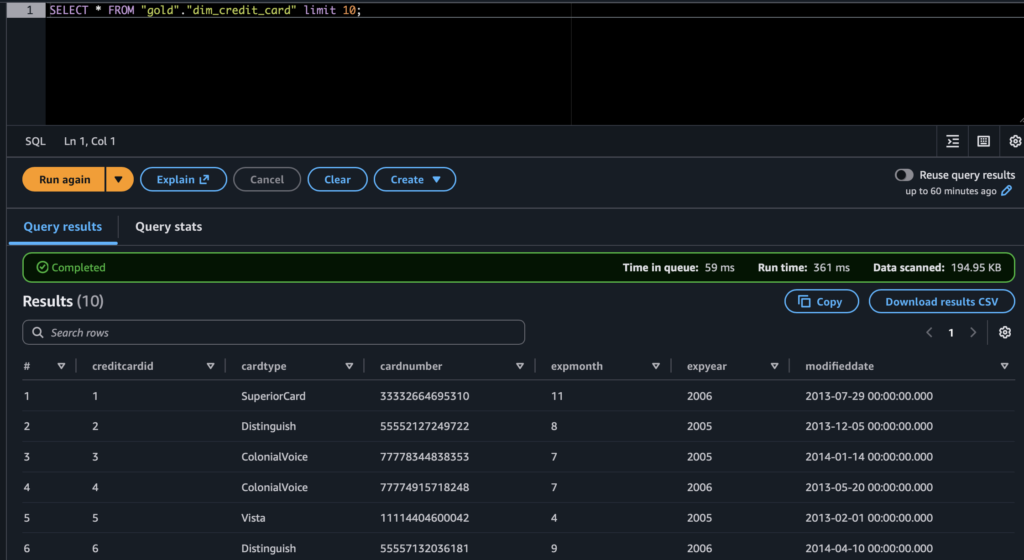
Tabelas criadas no Bigquery e também no Athena.
Bigquery
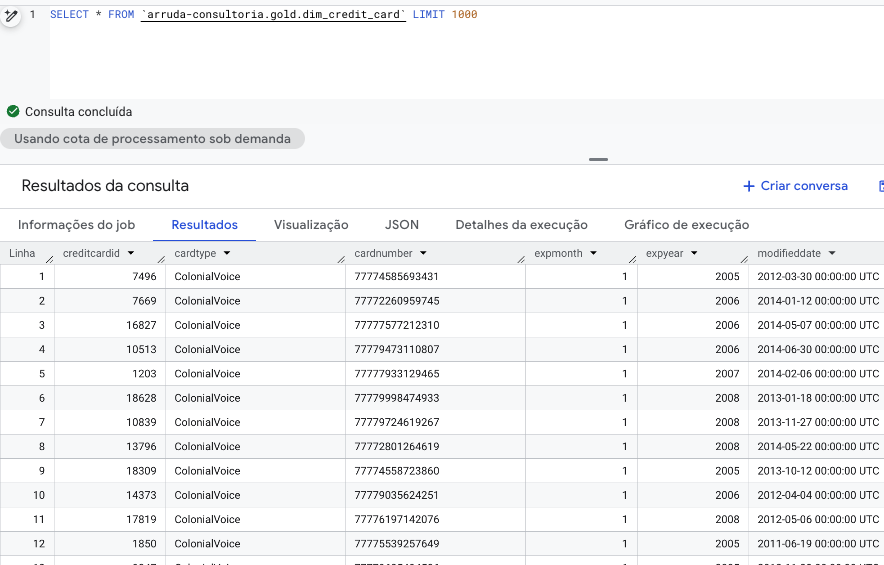
Athena
E para fechar, basta Orquestrar no Jenkins
Insights
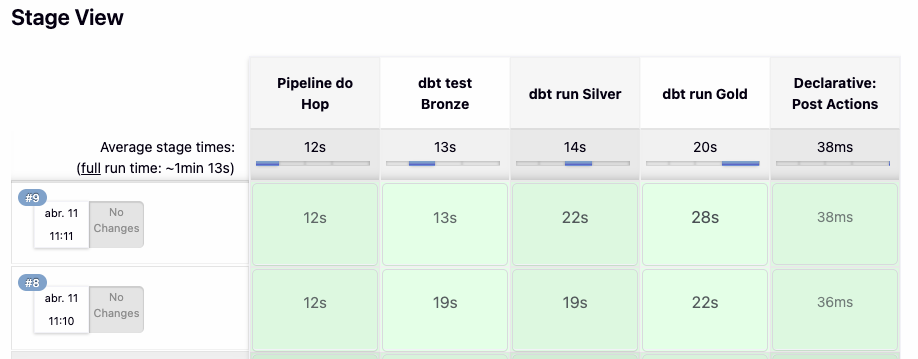
Com base nos testes realizados, alguns pontos ficaram claros:
- O tempo de ingestão com Apache Hop foi praticamente o mesmo entre os cenários
- A AWS apresentou melhor desempenho na validação da camada Bronze
- O Google BigQuery foi mais rápido na geração das tabelas nas camadas Silver e Gold
Além disso, existem outras variáveis importantes que podem ser analisadas, como:
- custo de processamento
- performance de leitura
- escalabilidade
- governança
Conclusão
Com base em análises como essa, conseguimos tomar decisões muito mais assertivas na escolha da arquitetura de dados.
A escolha deixa de ser baseada em opinião e passa a ser guiada por evidência.
No final, a pergunta não é:
Qual a melhor tecnologia mas sim Qual a Arquitetura faz mais sentido para o meu cenário?
Sempre fazem as suas provas de conceitos(POC).
Testem… Validem… Comparem….
E deixem os dados decidirem.
Muito Obrigado.
Rafael Arruda.