
Durante muito tempo, trabalhar com dados significou responder a uma pergunta básica:
Com que frequência esses dados serão atualizados?
Na prática, essa resposta normalmente era algo como:
- D-1.
- a cada 8 horas.
- a cada 1 hora.
A partir disso, toda a orquestração era construída definindo quando cada pipeline deveria ser executado.
A lógica tradicional: o tempo manda no dado
No modelo clássico, definir que um pipeline roda a cada 1 hora significa que ele será executado de hora em hora, tenha dado novo ou não.
O pipeline roda simplesmente porque o horário chegou.
Esse modelo funciona, mas traz efeitos colaterais bem conhecidos:
- execuções vazias.
- custo desnecessário.
- dependências rígidas.
- pipelines rodando apenas porque “chegou no horário”
Nesse cenário, o tempo controla o dado.
A proposta das Dynamic Tables
As Dynamic Tables surgem com uma proposta diferente.
Em vez de pensar “a cada X tempo preciso executar este pipeline”, a pergunta passa a ser outra:
Por quanto tempo essa tabela pode ficar sem ser atualizada?
Essa mudança parece sutil, mas é fundamental.
Se a resposta for uma hora, então esse passa a ser o atraso máximo permitido para aquela tabela — e não um agendamento fixo de execução.
Dynamic Table com TARGET_LAG = 1 hora
Exemplo de um Script de criação.
CREATE OR REPLACE DYNAMIC TABLE dt_customers
TARGET_LAG = '5 minute'
WAREHOUSE = 'COMPUTE_WH'
AS
select
coalesce(upper(raw:"customer_id"::string),'N/A') as customer_id,
coalesce(upper(raw:"company_name"::string),'N/A') as company_name,
coalesce(upper(raw:"contact_name"::string),'N/A') as contact_name,
coalesce(upper(raw:"contact_title"::string),'N/A') as contact_title,
coalesce(upper(raw:"country"::string),'N/A') as country,
coalesce(upper(raw:"city"::string),'N/A') as city,
coalesce(upper(raw:"address"::string),'N/A') as address,
coalesce(upper(raw:"postal_code"::string),'N/A') as postal_code,
coalesce(upper(raw:"phone"::string),'N/A') as phone,
coalesce(upper(raw:"fax"::string),'N/A') as fax,
current_timestamp as created_at
from bronze_customers
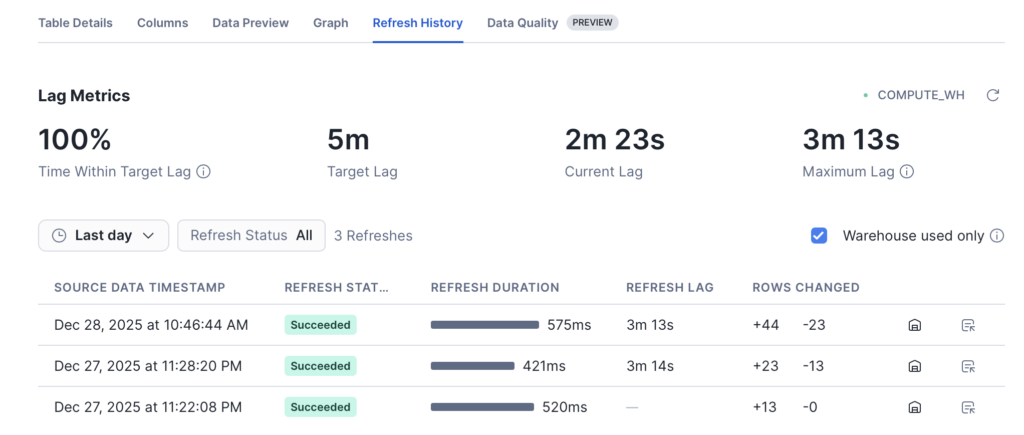
Também conseguimos ter a visibilidade do histórico de atualizações.
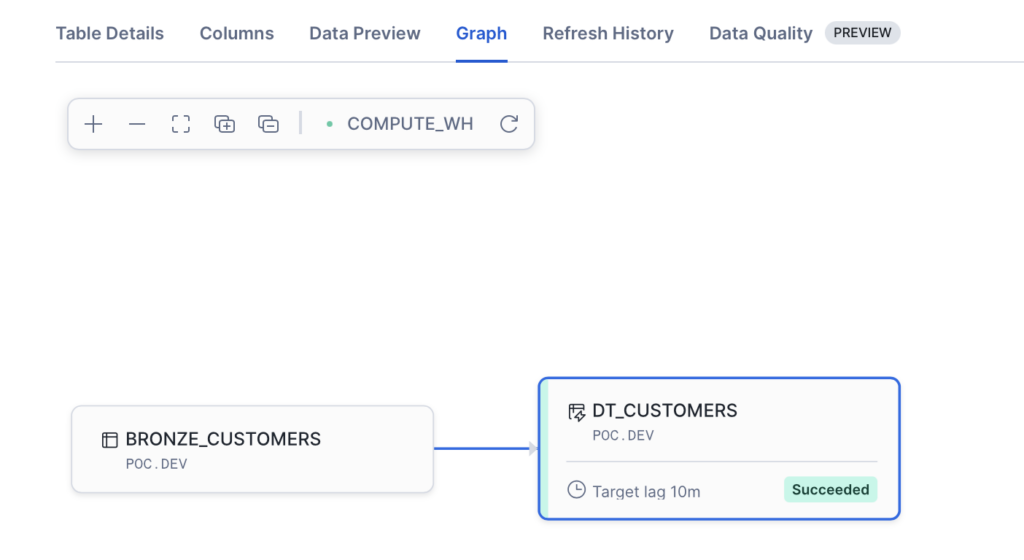
E como nessa abordagem nosso pipeline atualiza sem precisar de uma Task para isso a forma da gente ver a linhagem de dados é clicar no Graph.
Utilize com moderação.
Dynamic Tables não são apenas mais um recurso do Snowflake.
Elas representam uma mudança na forma de pensar pipelines de dados.
Em vez de arquitetar soluções baseadas em horários fixos, passamos a trabalhar com contratos de atualização, onde o mais importante não é quando o pipeline roda, mas qual é o atraso máximo aceitável para o dado.
Esse modelo reduz execuções desnecessárias, evita pipelines rodando sem dado novo e torna o custo mais previsível, já que o processamento acontece apenas quando realmente há mudança nos dados.
Ao mesmo tempo, é importante reconhecer o trade-off que essa abstração traz.
Em arquiteturas baseadas em Tasks, a orquestração explícita e o DAG visual oferecem uma visibilidade muito clara das dependências entre pipelines, algo especialmente valioso em camadas como a Silver, onde debugging e rastreabilidade costumam ser mais frequentes.
Com Dynamic Tables, essa visibilidade operacional deixa de estar no agendamento e passa a estar no próprio modelo de dados e nas dependências declaradas. Isso exige mais disciplina arquitetural, bons padrões de nomenclatura e, em muitos casos, apoio de ferramentas de lineage para manter a observabilidade.
Por isso, Dynamic Tables não devem ser vistas como uma substituição automática para todas as camadas da arquitetura. Elas funcionam muito bem quando existe um SLA claro e consumo recorrente, mas devem ser usadas com consciência, especialmente em contextos onde a visibilidade operacional é crítica.
Entender esses trade-offs é o que permite usar Dynamic Tables de forma madura — aproveitando seus benefícios sem abrir mão de controle e previsibilidade.
Muito Obrigado.
Rafael Arruda