


No mês passado, tivemos a 1ª turma do Data Speed, onde abordamos como implementar uma Stack Moderna de Dados. Mais do que as ferramentas — que são resultado de 3 anos de projetos — o principal ponto é a mudança de paradigma: a cloud será, cada vez mais, apenas o local onde os dados são armazenados e acessados, sem ficar refém de nenhuma plataforma.
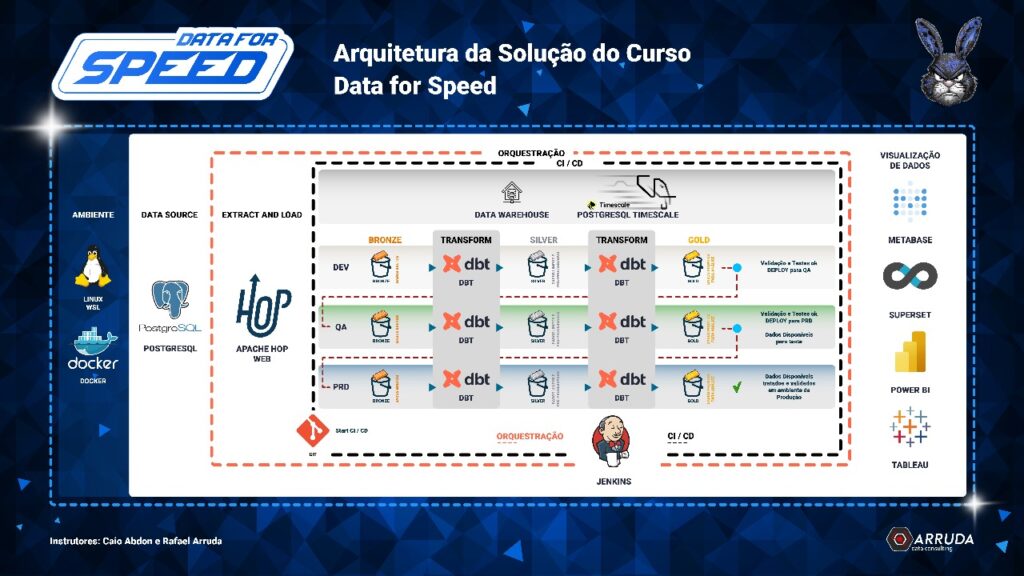
Então na Arquitetura acima temos as seguintes tecnologias:
- Toda Stack em Containers.
- Apache Hop Para ingestão dos dados.
- DBT para Transformação e validação dos dados.
- Postgres para DW.
- Jenkins como CI/CD e Orquestração.
Agora imagine o seguinte cenário: seu gerente prefere uma solução em nuvem. Em vez de armazenar os dados no PostgreSQL, você os coloca no armazenamento da cloud escolhida.
Se for Google Cloud, usamos o Hop para gravar no Cloud Storage e o dbt atua sobre o BigQuery.
Se for AWS, gravamos no S3 e podemos usar Athena ou Redshift.
Se for Snowflake ou Databricks, a stack continua a mesma — já que ambas se integram nativamente com os storages das três principais clouds.
Todo o restante da Stack não mudaria.
Exemplo prático com SnowFlake
Snowflake tem integração com as três principais Clouds:
- AWS.
- Google Cloud.
- Azure.
Para este exemplo iremos gravar os dados no S3 da Amazon, porém o processo seria exatamente o mesmo para as demais clouds.
Para começar, usamos o Apache Hop para ler dados de um banco PostgreSQL e gravá-los no S3, em formato Parquet.
Cada tabela possui sua respectiva pasta e arquivos:
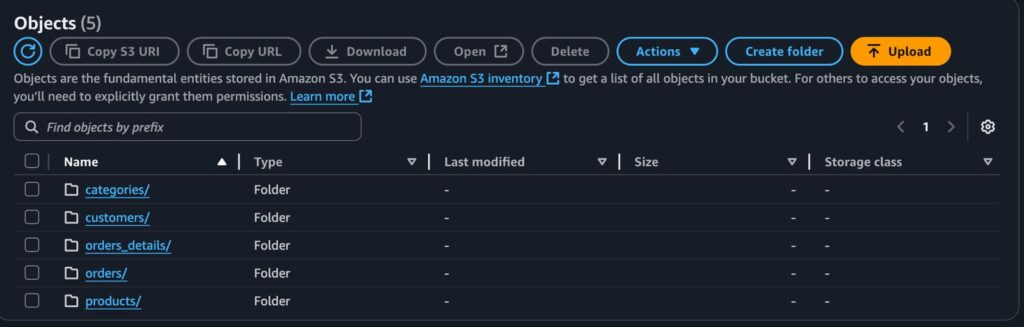
A partir daqui temos duas formas de acessar esses dados do Snow, Utilizando Python ou SQL.
Com Python teriamos um Script para ler esses dados e gravar em tabelas nativas do Snowflake.
Mas se você não tem muita habilidade com Python, fique tranquilo pois é possível fazer este processo todo utilizando somente SQL.
Para isso será necessário Criar um Stage informando alguns dados da sua conta da AWS ou da sua Cloud que utiliza na sua empresa.
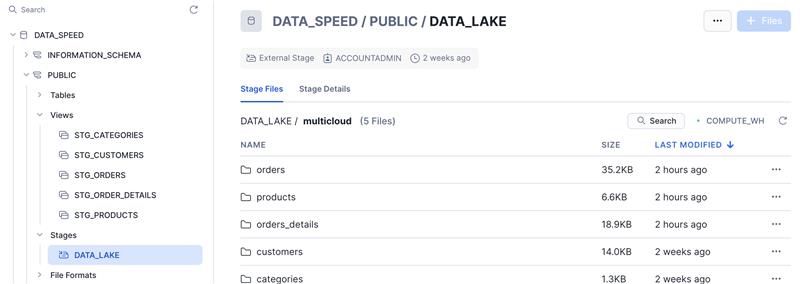
Dessa forma já conseguimos acessar os nossos dados do S3 dentro do Snowflake.
Agora, ao criar um Arquivo SQL, vamos poder manipular esses dados.
Uma alternativa seria criar a tabela já com os seus devidos campos, mas se no amanhã é adicionado novas colunas nesses arquivos do S3, teriamos que alterar aqui também.
Então uma prática que resolvi adotar foi criar a tabela com uma única coluna para armazenar os dados.
E na camada Silver tratar esses dados, mas isso será feito lá no DBT.
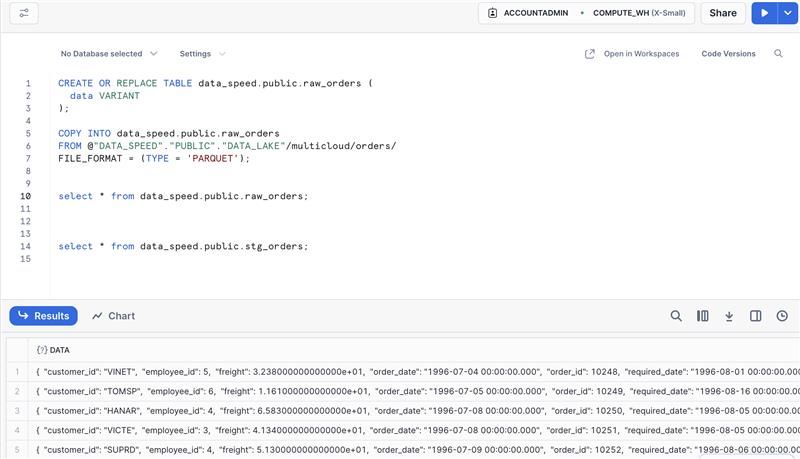
Camada Bronze -> raw_orders.
Camada Silver -> stg_orders
/*
SELECT
data:customer_id::VARCHAR AS customer_id,
data:employee_id::INT AS employee_id,
data:freight::DECIMAL(10, 2) AS freight,
data:order_date::TIMESTAMP AS order_date,
data:order_id::INT AS order_id,
data:required_date::TIMESTAMP AS required_date,
data:ship_address::VARCHAR AS ship_address,
data:ship_city::VARCHAR AS ship_city,
data:ship_country::VARCHAR AS ship_country,
data:ship_name::VARCHAR AS ship_name,
data:ship_postal_code::VARCHAR AS ship_postal_code,
data:ship_via::INT AS ship_via,
data:shipped_date::TIMESTAMP AS shipped_date
FROM {{ source('bronze', 'raw_orders') }}
*/Com o arquivo stg_orders.sql criado ao executar o comando dbt run.
A Tabela foi criada com sucesso.
E assim temos a nossa tabela de pedidos na camada silver.
E ao gerar a documentação do DBT, temos a linhagem de dados.

Com o Apache Hop fazendo a ingestão dos dados, DBT para transformação e o DW no Snowflake, aonde entraria o Jenkins neste processo?
O Jenkins é uma peça vital nessa Arquitetura mas ele entra no final, utilizamos ele em duas etapas:
- Orquestração de todo o Pipeline.
- CI/CD.
No Link abaixo gravei um vídeo demonstrando como funciona na prática o processo de CI/CD desde o commit da Branch até o deploy.
Como funciona o CI/CD com Jenkins na prática
O vídeo foi gravado com a Stack original utilizando o Postgres como DW, mas o processo seria praticamente o mesmo com Snowflake.
Veja que na nossa Arquitetura do Data Speed, você pode ter o seu DW num banco postgres, mas também seu DW pode estar na Cloud, como acabamos de demonstrar nesse artigo, porém todo o restante não muda em nada.
Caso já utiliza AWS e prefere disponibilizar os seus dados na Amazon temos um artigo parecido com este mas utilizando S3 e Athena.
Replicando a Stack Data Speed na AWS
Quer aprender a implementar essa Stack do zero?
Conheça o projeto Data Speed e leve seus projetos a um outro nível:
https://dataforspeed.arrudaconsulting.com.br/
Muito Obrigado.
Até o próximo artigo
Rafael Arruda