

No artigo anterior (https://arrudaconsulting.com.br/dbt-controle-codigos-sql/), falei um pouco sobre a utilização da ferramenta dbt (Data Build Tool) e sua capacidade de organização e versionamento de códigos SQL. Neste post, vou me aprofundar nas funcionalidades de documentação e testes, que tornam o dbt ainda mais poderoso no gerenciamento de projetos de dados.
Na pasta models, podemos inserir todos os arquivos diretamente nela ou organizá-los em subpastas. Independentemente da estrutura adotada, é possível criar um arquivo .yml de documentação para cada subpasta, facilitando a separação por domínio ou área. Caso prefira, também é válido manter um único arquivo .yml na raiz da pasta models, centralizando a documentação de todos os modelos.

Após essa organização, ao editar o arquivo .yml, podemos indicar os modelos presentes no projeto, referindo-nos diretamente a cada arquivo .sql da pasta models. Em seguida, é possível documentar o nome das tabelas, suas colunas e, quando necessário, definir testes de integridade como not_null, unique, accepted_values e relationships.
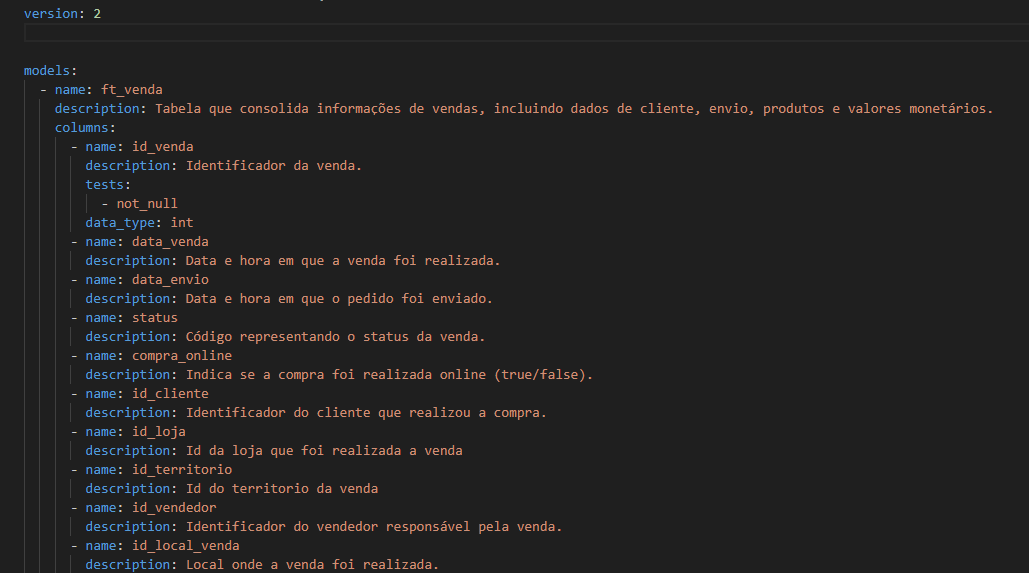
Como podemos ver na imagem acima, primeiro definimos o nome da tabela — que deve ser o mesmo nome do arquivo .sql (sem a extensão) — e em seguida adicionamos a descrição da tabela. Essa descrição já serve como documentação e pode indicar, por exemplo, a área de negócio à qual ela pertence (como Financeiro, RH, Logística, etc.), os tipos de dados que ela armazena e outras informações relevantes sobre seu uso.
Logo abaixo, passamos a descrever as colunas da tabela, preenchendo uma a uma. Para cada coluna, também é possível adicionar uma descrição e definir testes automatizados. Entre os testes mais comuns estão:
- not_null: garante que a coluna não contenha valores nulos
- Unique: assegura que os valores sejam únicos na coluna
- accepted_values: restringe os valores possíveis a uma lista predefinida: values: [‘PF’, ‘PJ’]
- Relationship: verifica se a coluna está relacionada corretamente a outra tabela, como uma chave estrangeira: to: ref(‘dim_loja’) field: id_loja
A opção not_null faz com que o dbt verifique se existe algum valor nulo em uma coluna que deve conter obrigatoriamente dados, ajudando a garantir a integridade da informação.
A opção unique garante que todos os valores da coluna sejam únicos, ou seja, que não haja repetições — algo essencial em colunas que representam chaves primárias, por exemplo.
A opção accepted_values permite definir uma lista de valores válidos para a coluna, o que é especialmente útil para capturar possíveis erros de entrada vindos da fonte de dados, como valores inesperados ou fora do padrão.
A opção relationships é utilizada quando um modelo faz referência a outro modelo. Com ela, o dbt verifica se todos os valores da coluna referenciada realmente existem no modelo de destino, funcionando como uma verificação de integridade referencial — semelhante a uma chave estrangeira em bancos de dados relacionais.
Depois de definir os testes em seus modelos, você pode executá-los com o comando: dbt test –select silver.ft_venda, você também pode executar os testes de toda uma pasta ao usar apenas o nome da pasta: (dbt test –select silver) Isso irá rodar todos os testes definidos dentro dos modelos presentes na pasta silver.
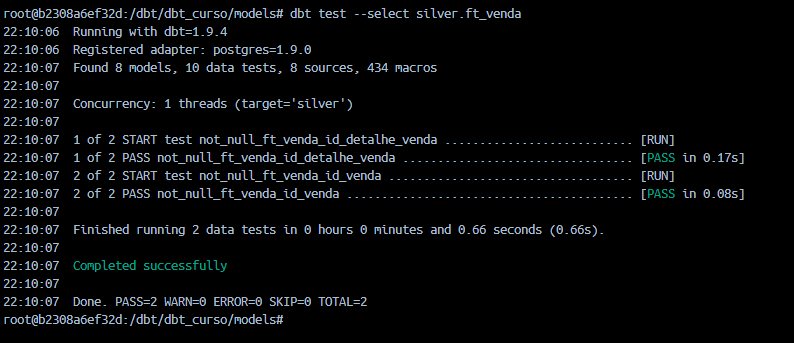
Com isso, podemos verificar que os testes de dados foram aplicados corretamente.
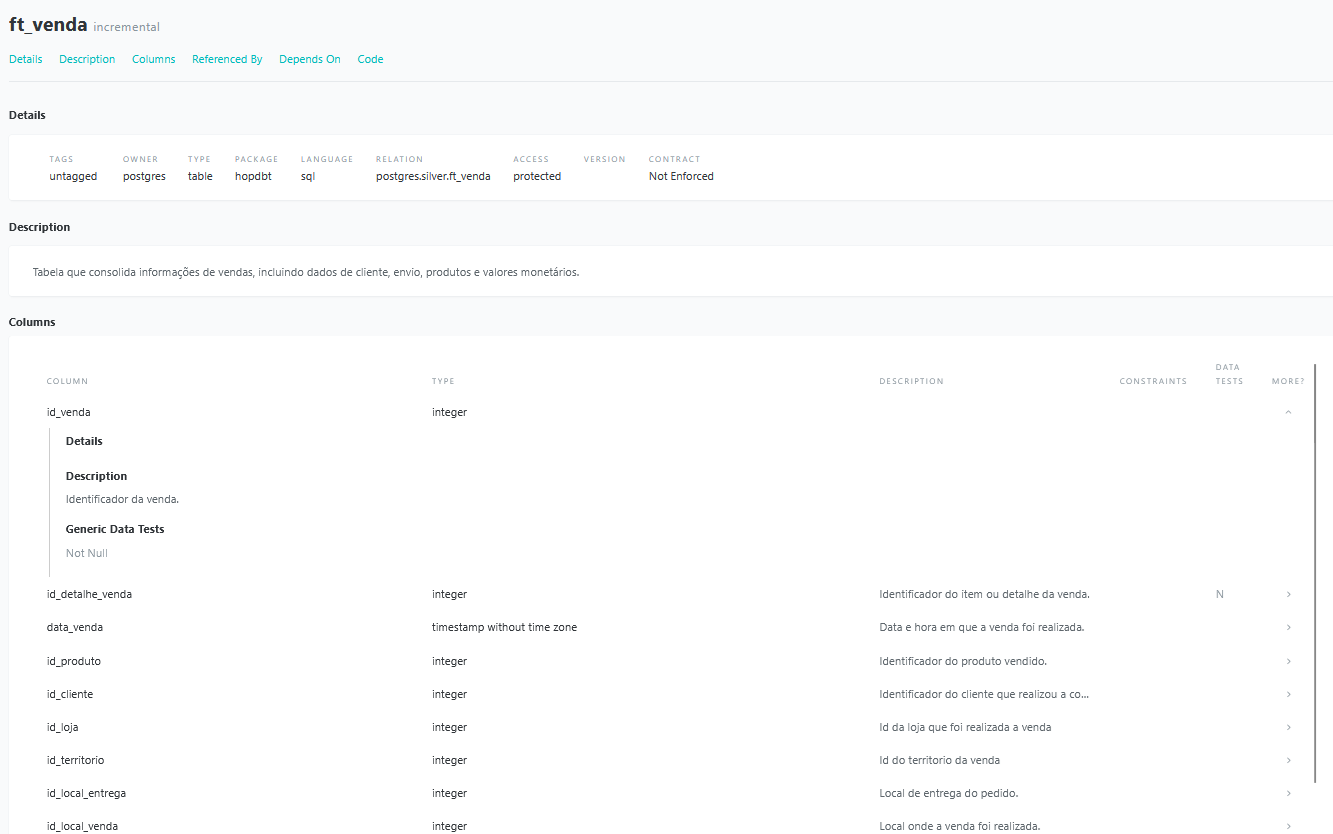
Após configurar todas essas etapas — que já contribuem significativamente para a documentação do projeto — podemos executar o comando dbt docs generate. Esse comando irá gerar um arquivo .json contendo todas as informações de modelos, colunas, descrições e testes definidos.
Em seguida, para visualizar essa documentação de forma interativa em um navegador, basta executar dbt docs serve –port 9000.
O parâmetro –port é opcional; se não for especificado, o dbt utilizará a porta padrão 8080. Após iniciar o servidor local, você poderá acessar a documentação do projeto diretamente pelo navegador.
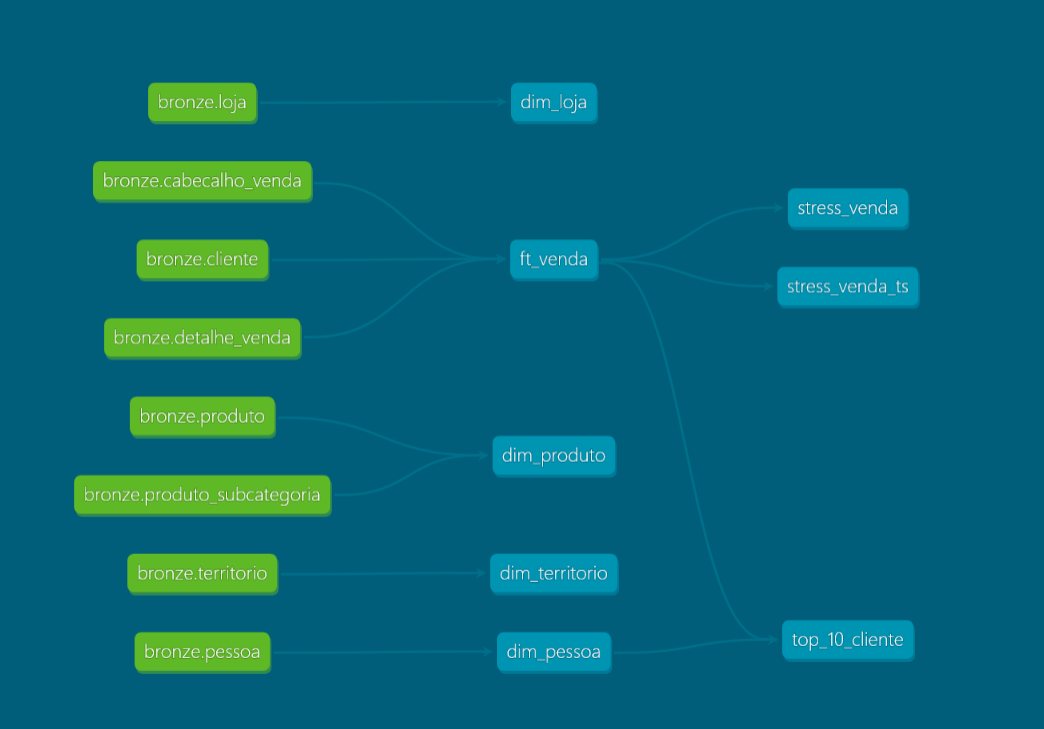
Além disso, ao acessar a documentação gerada pelo dbt, podemos clicar no botão azul no canto inferior direito da tela para visualizar a linhagem dos dados (data lineage). Essa funcionalidade permite entender, de forma gráfica e interativa, como os modelos se conectam entre si — desde as fontes até as tabelas finais — facilitando o rastreamento de dependências e o entendimento do fluxo de dados no projeto.
Agora, nosso projeto conta com testes automatizados para validação dos dados, está totalmente documentado e ainda oferece a possibilidade de disponibilizar essa documentação de forma acessível a todos, diretamente pelo navegador.
Se quiser ter acesso a um conteúdo mais detalhado combinando DBT com outras ferramentas como Apache Hop, Jenkins, Git e Postgres, se inscreva no evento.
E com certeza os seus projetos irão mudar de patamar após este rico conteúdo.
Muito Obrigado.
E até o próximo artigo.