

Olá,
O Apache Hop é uma excelente solução para implementar um Data Warehouse ou um Data Lake, seja em um ambiente On-Prem ou na Cloud, e uma etapa importante nessa etapa é a validação dos dados.
E é justamente esste tema que iremos abordar nesse artigo.
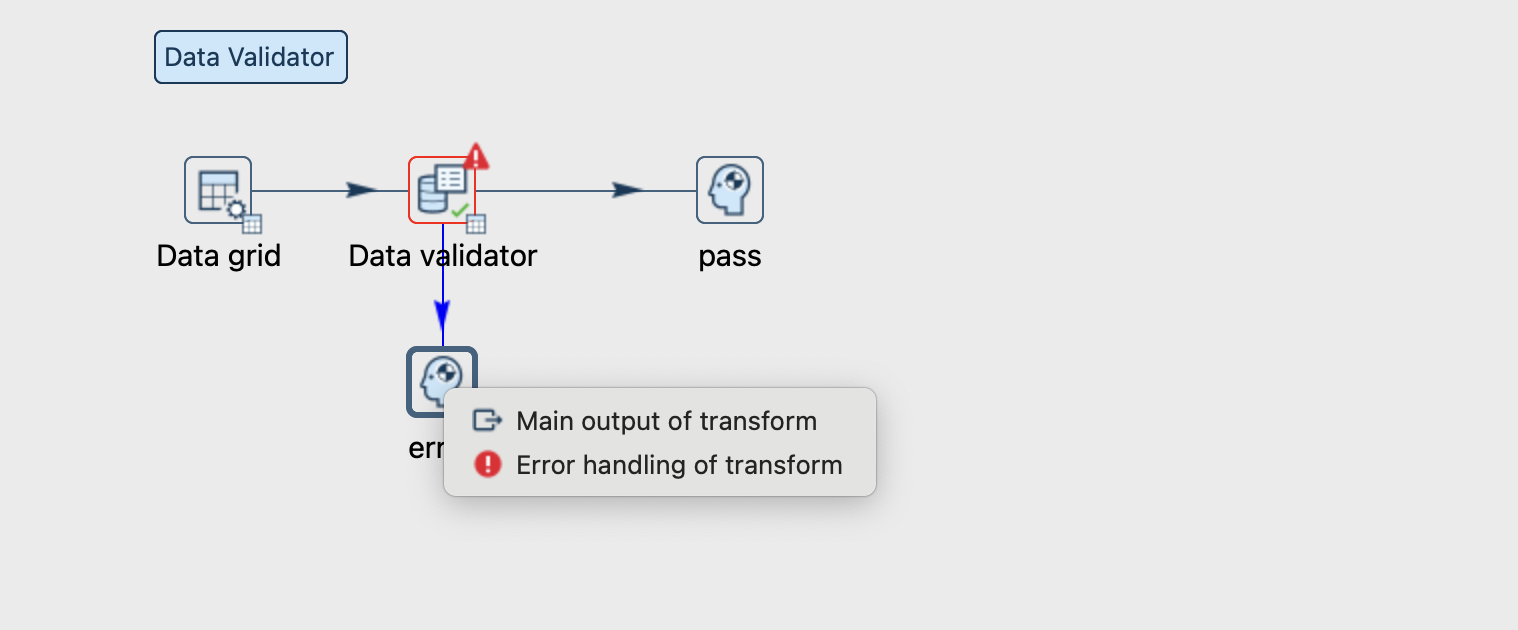
Você já ouviu falar do Step: Data Validator?
Próprio nome já diz, é um step aonde conseguimos criar algumas validações, ou condições se o fluxo irá seguir adiante ou não.
Imagina que a sua principal coluna está com alguns dados nulos, o que é melhor carregar esses dados errado mesmo? ou receber algum email ou alerta com os dados que precisa tratar, os dados que estiverem corretos, serão carregados normalmente.
A validação dos dados é uma etapa muito importante em qualquer projeto na área de dados.
Não basta apenas disponibilizar os dados, a informação precisa estar verificada e confiável também.
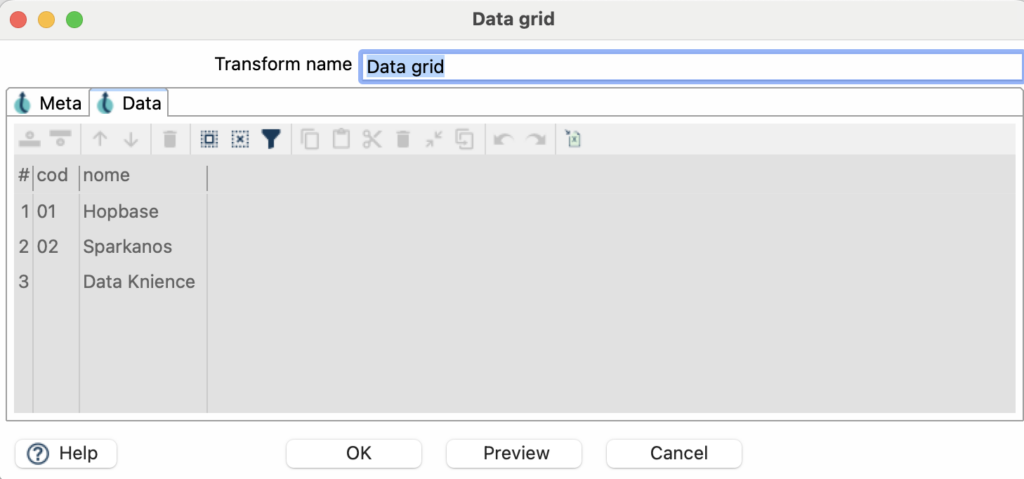
Para este exemplo, iremos utilizar duas colunas:
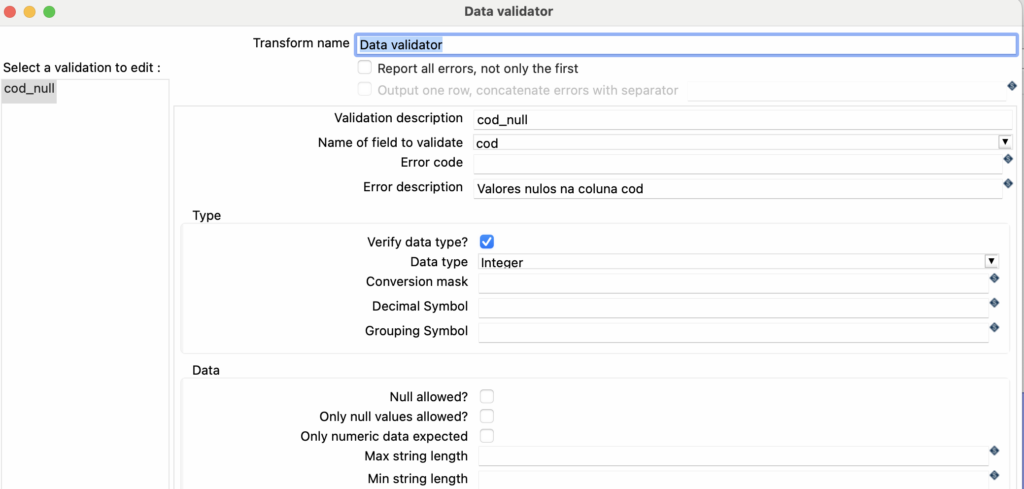
Ao adicionar o Step Data Validator, iremos clicar em “New Validation”, ao soliticar o nome dessa verificação iremos colocar: cod_null.
Iremos desabilitar a opção “Null allowed”, ou seja essa coluna cod, não pode receber dados nulos
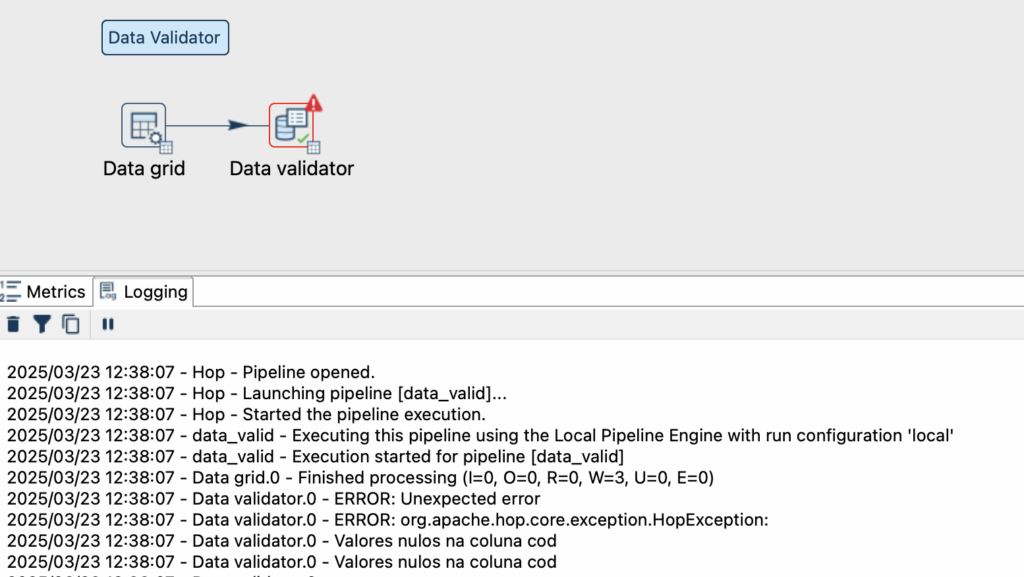
Ao executar o nosso pipeline, verificamos que a validação funcionou, como temos um registro nulo na coluna cod, o pipeline deu erro, e não seguiu adiante.
Mas imagina que numa carga de 90 mil registros, um registro apenas não passou nessa validação, não iremos carregar todos esses registros que estão corretos, por conta de um registro?
Não parece algo muito inteligente a se fazer, mas ai que entra o Error Handling.
Aonde todos os registros com erro serão encaminhados para o Error Handling.
Então agora utilizamos dois step Dummy, para separar os dados, o que passaram na validação e os que não passaram.
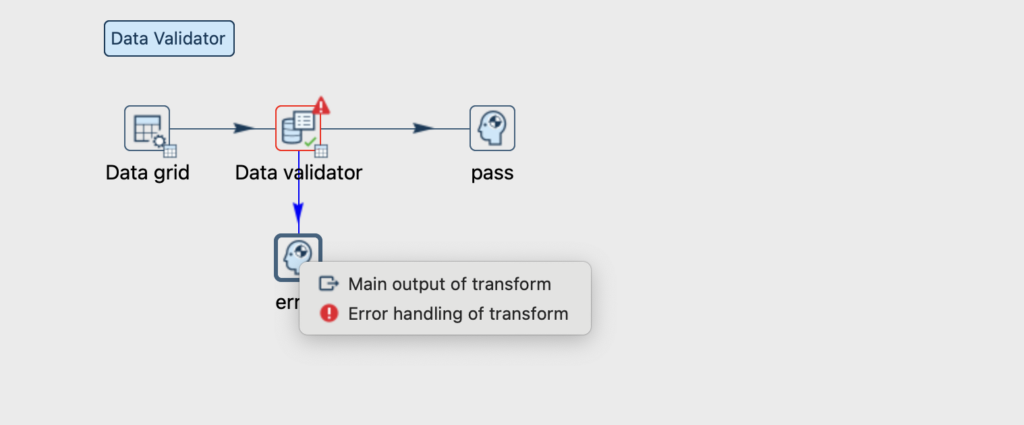
E ao executar o nosso pipeline, temos a seguinte situação.
Registros que passaram pela validação: 2.
Registros que reprovaram na validação: 1.

O Step error nós poderíamos configurar para enviar um e-mail ou alerta para a área responsável corrigir o dado direto no sistema de origem. Já o Step pass, permitiria que o dado seguisse adiante no fluxo de dados.
Esse foi apenas um exemplo simples do poder do Data Validator. Com ele, é possível criar pipelines mais seguros, confiáveis e inteligentes.
Quer aprender outros Steps do Apache Hop?
Então veja a nossa aula com 2 horas de conteúdo de Apache Hop.
Muito obrigado e até o próximo artigo.
Rafael Arruda.