

Gerenciando memória para Agentes de IA
A capacidade de retenção de informações é um dos maiores desafios na construção de sistemas de agentes de IA colaborativos. Embora esses agentes consigam manter o contexto imediato de uma conversa, eles frequentemente esquecem informações importantes entre sessões. Isso limita a continuidade e a eficácia da colaboração.
A complexidade surge porque os modelos de linguagem (LLMs e SLMs) são não-determinísticos. Interações quase idênticas podem resultar em respostas diferentes, e pontos cruciais, como definições de projeto ou preferências do cliente, são facilmente perdidos em conversas longas.
O futuro da Engenharia de IA reside na habilidade de reter o que importa, esquecer o que não importa e transformar dados brutos em inteligência genuína.
Memória na Arquitetura do Agente
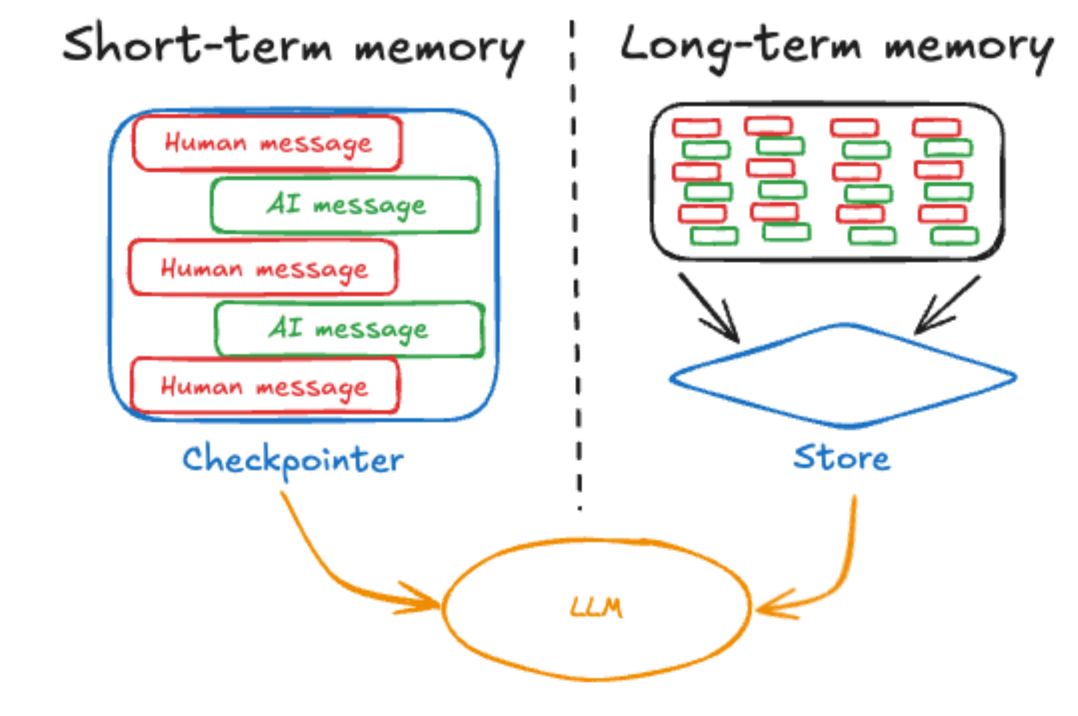
Em uma solução de Agente de IA, a memória é um conjunto de componentes externos orquestrados. Os dois tipos de memória são definidos pela longevidade e pelo mecanismo de acesso à informação:
-
- Memória de Curto Prazo (Short-Term Memory – STM): Mantém o contexto imediato da sessão atual, através do histórico bruto e da janela de contexto.
-
- Memória de Longo Prazo (Long-Term Memory – LTM): Armazena conhecimento persistente entre sessões e interações, podendo ser acessados através de Bancos de Dados Vetoriais, Bancos de Grafos e outras estruturas persistentes.
O Papel do Cache e a Memória de Curto Prazo
A Memória de Curto Prazo (STM) é o histórico de conversação que está sendo inserido no prompt a cada nova interação. É aqui que o Redis ou outros sistemas de cache se tornam cruciais na arquitetura:
-
- Redis como Cache de Histórico: Em vez de fazer uma chamada a um banco de dados persistente a cada interação da conversa, o histórico da sessão atual é armazenado no Redis. Isso proporciona uma recuperação ultrarrápida (baixa latência), essencial para manter a fluidez do chat e evitar que o agente pareça lento.
-
- Gestão de Sessão (TTL): O Redis permite definir um Tempo de Vida (TTL) para as chaves de memória. Se o usuário abandonar a sessão por 30 minutos, o TTL expira, e a memória é automaticamente descartada
O uso do Redis transforma a STM em um serviço eficiente e otimizado.
Memória de Longo Prazo (LTM)
A LTM é o coração da inteligência e da personalização dos Agentes. Ela lida com a informação que precisa ser mantida e consultada em diferentes sessões ou por diferentes agentes.
A inteligência da LTM reside na forma como o agente transforma a informação e a recupera de maneira contextual:
- Memória Semântica (Similaridade): Onde a informação é convertida em vetores (embeddings) e armazenada em bancos de dados vetoriais (como Pinecone, Chroma, ou a funcionalidade Vetorial do próprio Redis). A recuperação é baseada no significado contextual, essencial para o RAG.
- Memória Estruturada (Fatos e Relações): Para fatos e relações complexas como preferências do usuário, instruções constantes ou respostas anteriores relevantes, a informação pode ser armazenada em bancos de dados de grafos (Graph Databases) ou bancos relacionais, garantindo a precisão da informação.
Transformando dados em conhecimento
Os sistemas mais avançados não apenas armazenam o histórico bruto, mas o processam ativamente. Isso exige que o agente executa um ciclo de três etapas para transformar dados em conhecimento:
- Observação: O agente recebe a informação do usuário ou de ferramentas.
- Reflexão/Sumarização: O agente utiliza um LLM (ou um SLM) para filtrar, resumir ou reformatar a observação, descartando ruído e consolidando o aprendizado em uma nova entrada de memória.
- Consolidação: Antes de responder, o agente busca a memória relevante (LTM) e a insere no prompt (contexto de curto prazo), garantindo que o conhecimento prévio influencie a resposta atual.
LLM as a Judge
Com a complexidade crescente dos agentes de IA, avaliar a qualidade de milhares de resultados gerados se tornou impraticável e não escalável para revisores humanos.
Com isso, surgiu a técnica LLM como Juiz, onde um LLM poderoso e de última geração é selecionado para atuar como um avaliador imparcial.
O processo funciona da seguinte forma:
- Entrada: O LLM avaliador recebe o resultado gerado pelo agente, o prompt original, um conjunto de dados e o modelo de pontuação selecionado
- Julgamento: Em seguida, ele é solicitado a avaliar o desempenho do agente em relação aos critérios definidos.
- Saída: O Juiz fornece uma pontuação e uma explicação qualitativa para seu julgamento.
Para aumentar a confiabilidade desse método, a técnica Cadeia de Pensamento (Chain-of-Thought – CoT) é frequentemente usada. Ao forçar o LLM a articular seu raciocínio passo a passo antes de dar a nota final.
Compartilhamento de Conhecimento e Valor Corporativo
As organizações bem-sucedidas serão aquelas que conseguirem mover seus agentes de IA de simples ferramentas para membros essenciais da equipe. Isso exige uma mudança fundamental, informações arquivadas devem se tornar conhecimento ativo (sustentado pela Memória de Longo Prazo), e a experiência de indivíduos deve ser convertida em inteligência coletiva acessível a todos.
Para que essa visão funcione em grande escala, a base de conhecimento deve ser planejada e mantida para garantir que o contexto de trabalho seja sempre factual, atualizado e facilmente acessível a todos os agentes e colaboradores
Desafios da Memória Persistente: Reflexão e Esquecimento
Quase todo o conhecimento de longo prazo dos agentes é transformado em vetores de números (embeddings) e guardado em Bancos de Dados Vetoriais. O principal desafio é: o que é importante o suficiente para ser armazenado, e o que pode ser descartado?
1- O Desafio da Sobrecarga de Dados
A tentação de armazenar tudo é grande, mas impraticável. Guardar cada frase e cada ação do Agente gera problemas:
- Custo e Escalabilidade: Conversas longas consomem muito espaço e elevam o custo de armazenamento e de processamento.
- Ruído Semântico: Armazenar dados desnecessários polui o banco de vetores. Na hora da busca, o Agente encontra tanto a regra crítica do projeto quanto uma informação que não é tão importante. Isso diminui a precisão da recuperação e aumenta o risco de alucinações.
2- O Desafio da Imprecisão Vetorial (LTM)
O problema mais técnico está na própria forma como a recuperação vetorial funciona, pois ela não é exata:
- Ambiguidade da Linguagem: A busca se baseia na similaridade de significado. No entanto, a linguagem é ambígua. O engenheiro precisa calibrar algoritmos para reduzir esse erro.
- O Risco do “Lixo Entra, Lixo Sai”: A qualidade dos embeddings é crucial. Se o vetor gerado para uma instrução importante for de baixa qualidade, o agente nunca mais conseguirá encontrar aquela informação, mesmo que ela esteja armazenada.
3- O Desafio da Reflexão e Governança
Para superar a sobrecarga e o ruído, o Agente precisa “refletir”, mas isso levanta novos desafios:
- Confiabilidade da Sumarização: O agente usa um LLM secundário para resumir e filtrar o histórico (Memória Episódica) em entradas concisas de LTM. Se o Agente resumir a informação de forma errada ou ignorar um detalhe crítico, essa memória essencial será perdida para sempre.
- Estratégia de Esquecimento: Como o sistema decide o que descartar ativamente? O descarte baseado em tempo (TTL) pode ser simples (ex: no Redis), mas pode remover informações valiosas. O agente precisa de regras claras para diferenciar o que pode ser esquecido por eficiência e o que deve ser mantido pela importância.
- O desafio futuro não é apenas guardar a informação, mas sim construir sistemas que possam julgar o valor, limpar o ruído e gerenciar o ciclo de vida do conhecimento de forma autônoma e confiável.
Fontes:
https://www.ibm.com/think/topics/ai-agent-memory
https://blog.langchain.com/memory-for-agents/
https://redis.io/blog/build-smarter-ai-agents-manage-short-term-and-long-term-memory-with-redis/
Muito Obrigado.
Moisés Arruda