No artigo anterior (https://arrudaconsulting.com.br/dbt-controle-codigos-sql/), falei um pouco sobre a utilização da ferramenta dbt (Data Build Tool) e sua capacidade de organização e versionamento de códigos SQL. Neste post, vou me aprofundar nas funcionalidades de documentação e testes, que tornam o dbt ainda mais poderoso no gerenciamento de projetos…
Neste artigo, vamos falar sobre a ferramenta dbt (Data Build Tool), focando especificamente na realização de cargas incrementais em nossos modelos. Ao criarmos um modelo e realizarmos a primeira carga de dados, pode não ser vantajoso executar uma carga completa (full load) a cada atualização, especialmente em projetos…
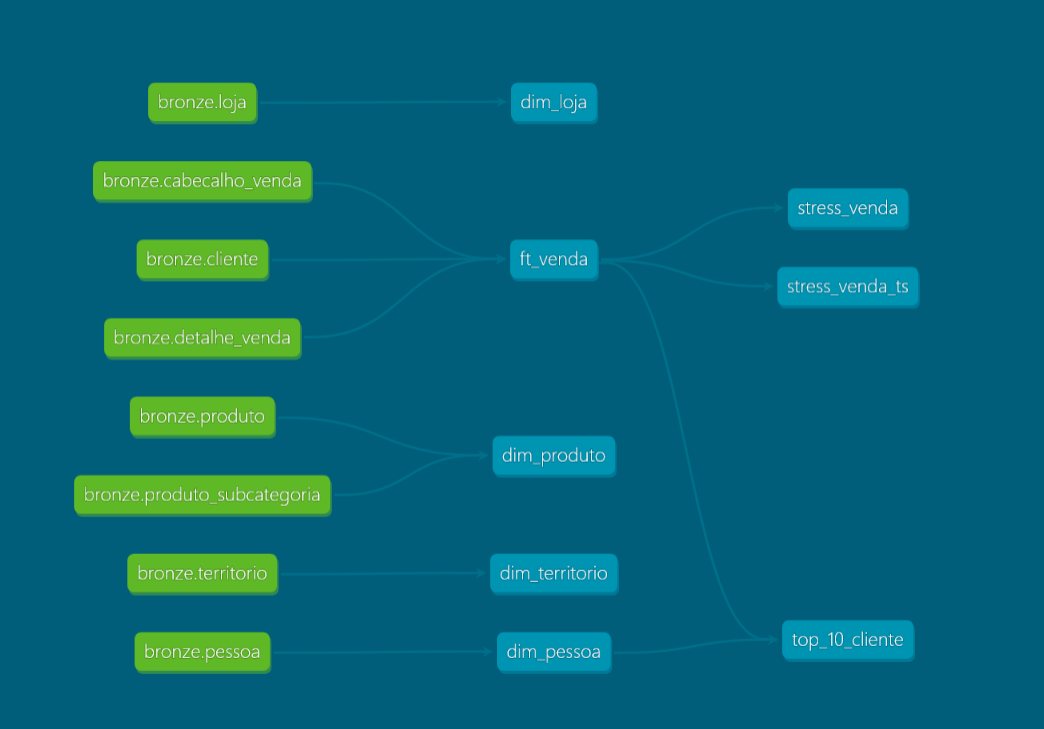
Neste artigo, vamos falar sobre a ferramenta dbt (Data Build Tool) e por que ela vem se tornando cada vez mais requisitada em ecossistemas de dados modernos, como Snowflake, BigQuery, Redshift, entre outros. Ao utilizarmos uma infraestrutura de dados moderna, é comum realizarmos diversas transformações por meio de…
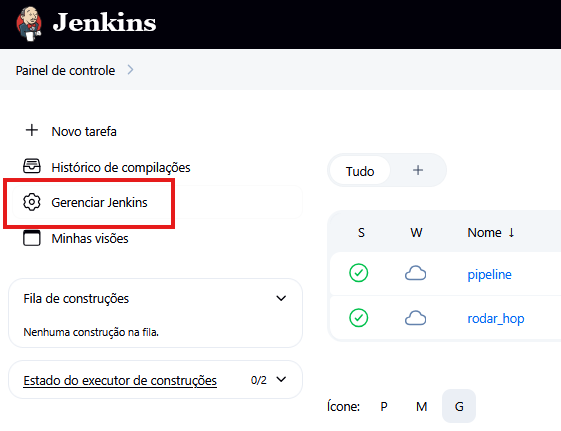
No artigo passado, mostramos as vantagens de utilizar o Jenkins para automação de jobs. E embora ele mostre o histórico das execuções — incluindo quantas falharam e quantas foram bem-sucedidas — ainda é um trabalho chato ter que abrir o console todos os dias para verificar os jobs…
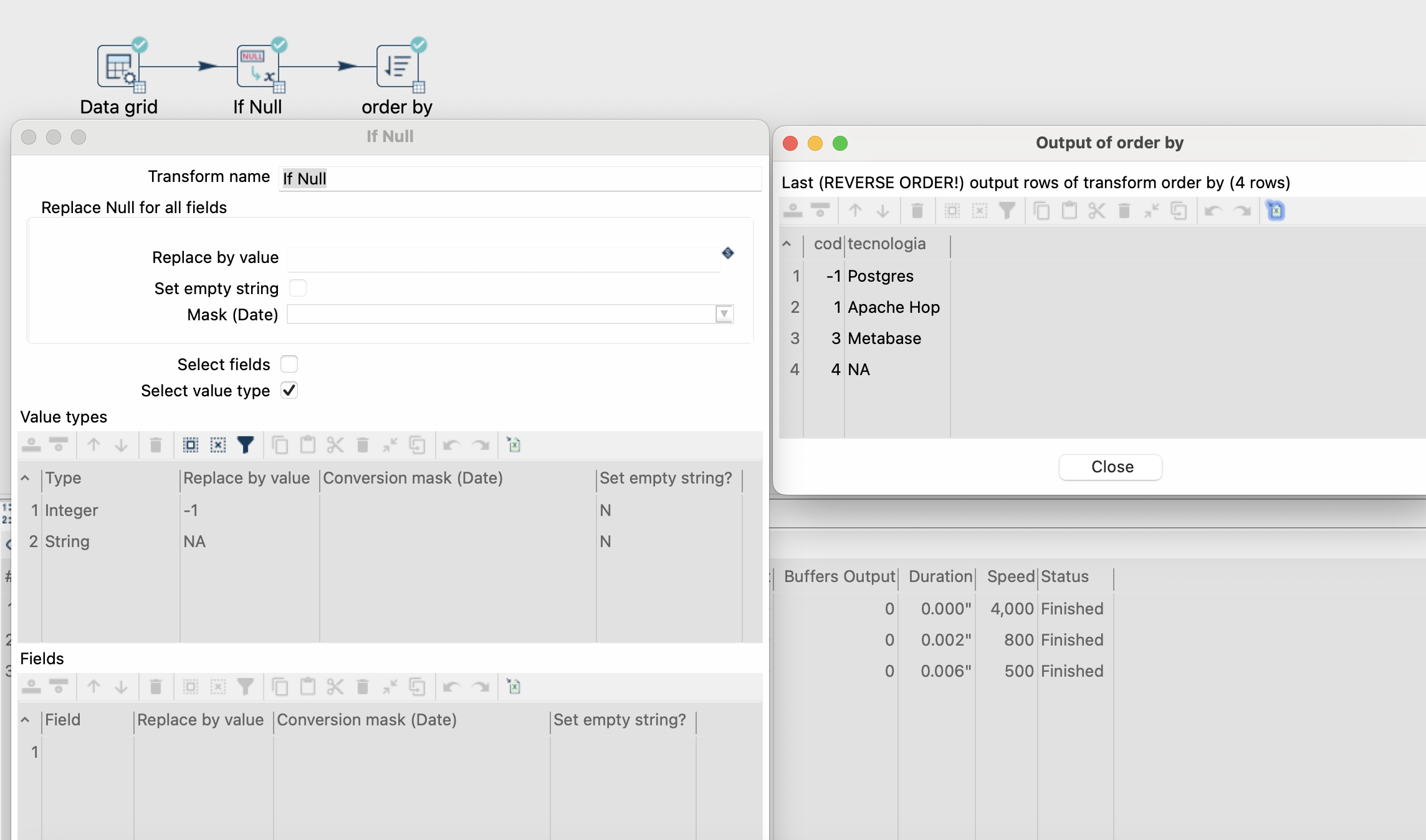
Olá, sempre que falamos de ETL, independente da ferramenta um dos tratamentos mais comuns são os valores nulos, normalmente temos duas abordagens nesse caso: Tratar os dados por coluna. Tratar os dados por tipo de dados. Quando tratamos os dados por coluna, no nosso ETL informamos o valor…
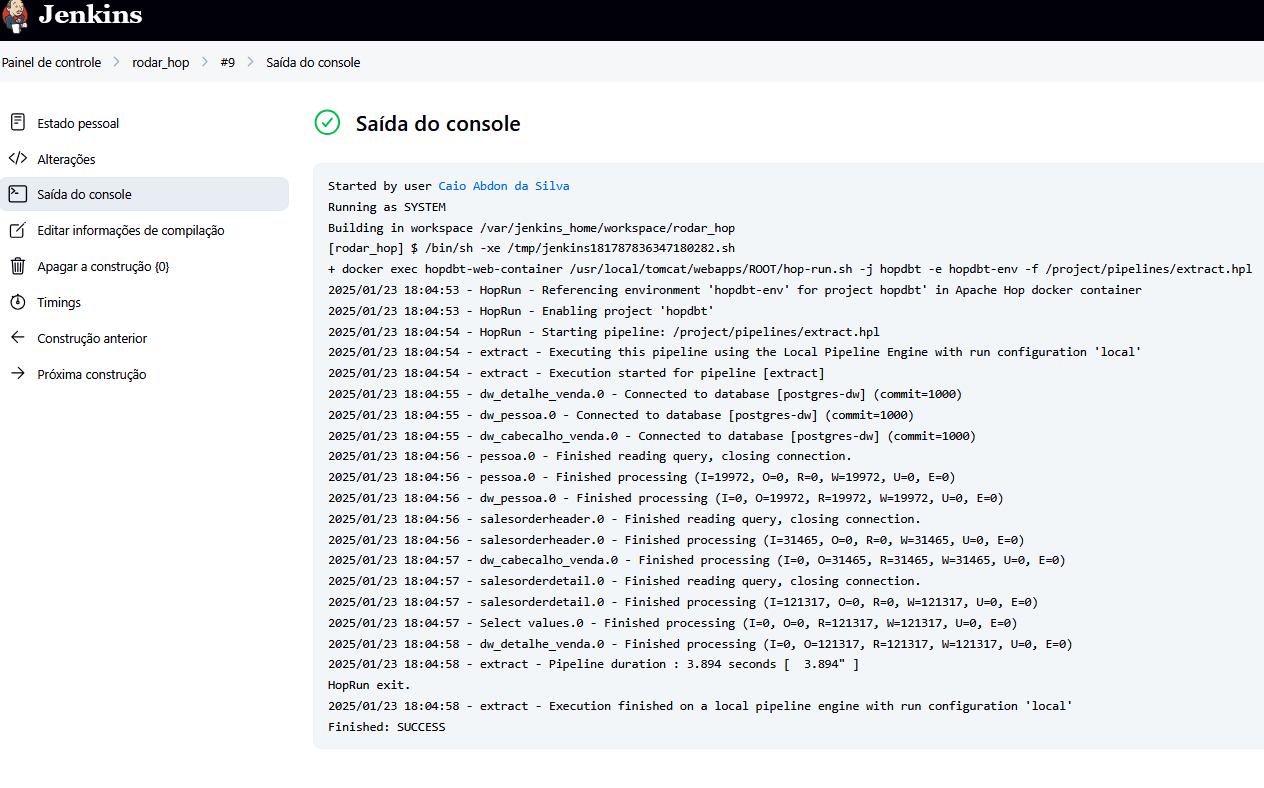
No mundo da engenharia de dados e desenvolvimento de software, a automação é indispensável. Seja para executar pipelines, scripts ou rotinas de manutenção, agendar tarefas de forma confiável faz toda a diferença. Embora sistemas operacionais como Linux (com o cron) ou Windows (com o Agendador de Tarefas) ofereçam…
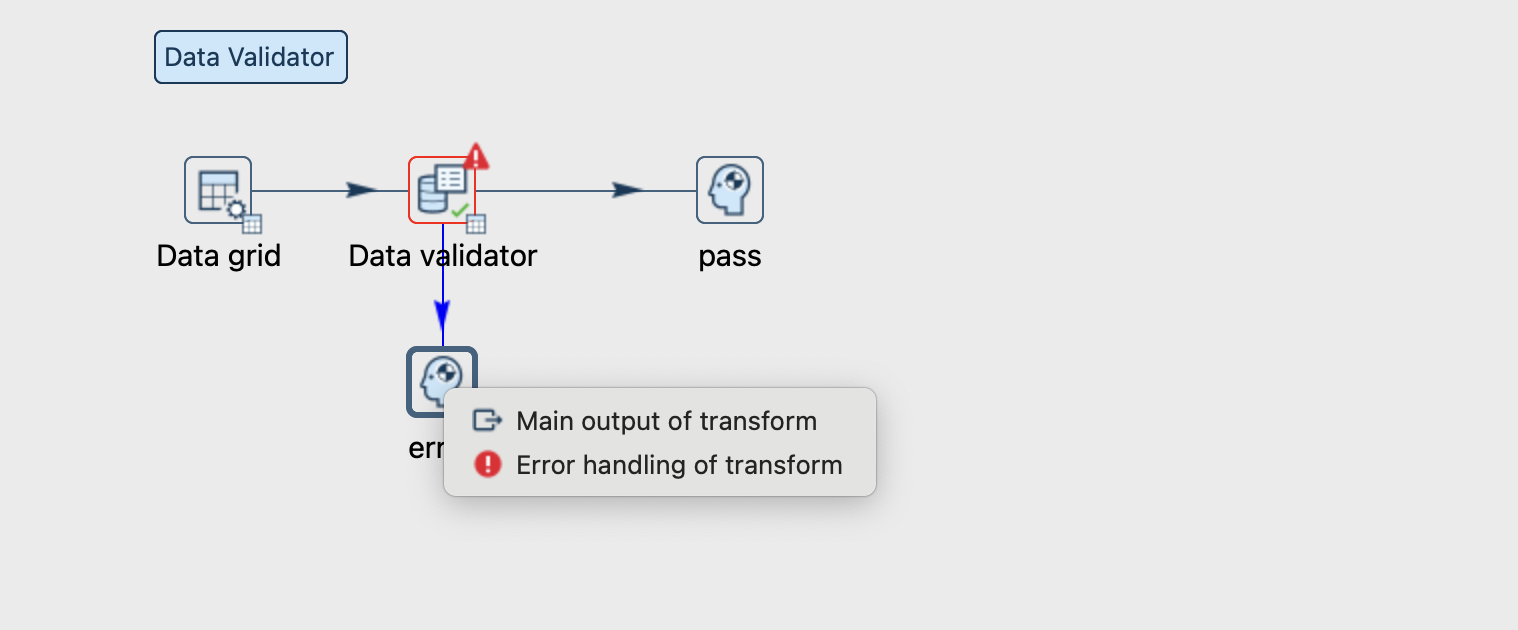
Olá, O Apache Hop é uma excelente solução para implementar um Data Warehouse ou um Data Lake, seja em um ambiente On-Prem ou na Cloud, e uma etapa importante nessa etapa é a validação dos dados. E é justamente esste tema que iremos abordar nesse artigo. Você já…
O KNIME Analytics Platform é uma ferramenta visuale intuitiva para análise de dados, automação de processos e ciência de dados. Ele permite que você crie fluxos de trabalho (workflows) sem precisar programar, o que o torna ideal para quem quer otimizar tarefas repetitivas de análise e transformação de…

O que é KNIME Analytics Platform? O KNIME Analytics Platform é uma poderosa ferramenta de ciência de dados e análise avançada. Esse software de código aberto e gratuito permite processar grandes volumes de dados, criar fluxos de trabalho automatizados e extrair insights valiosos para tomada de decisão. Instalar…
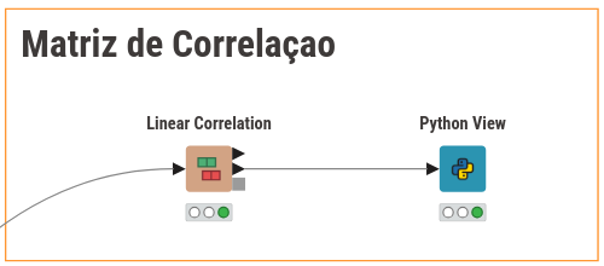
Introdução A análise de dados moderna exige ferramentas que equilibrem automação, flexibilidade e poder computacional. Um cientista de dados que precisa processar grandes volumes de informações pode optar por uma abordagem visual e automatizada no KNIME, simplificando a construção de workflows sem a necessidade de codificação manual. Por…