

Bom como sabe no mês passado, tivemos a 1ª Turma do Data Speed, abordando como Implementar uma Stack Moderna de Dados, mas talvez mais importante que as ferramentas que utilizamos, que basicamente é um compilado dos últimos 3 anos de projetos, ela muda um paradigma, que a Cloud vai ser basicamente aonde os dados serão armazenados e acessados, somente isso.
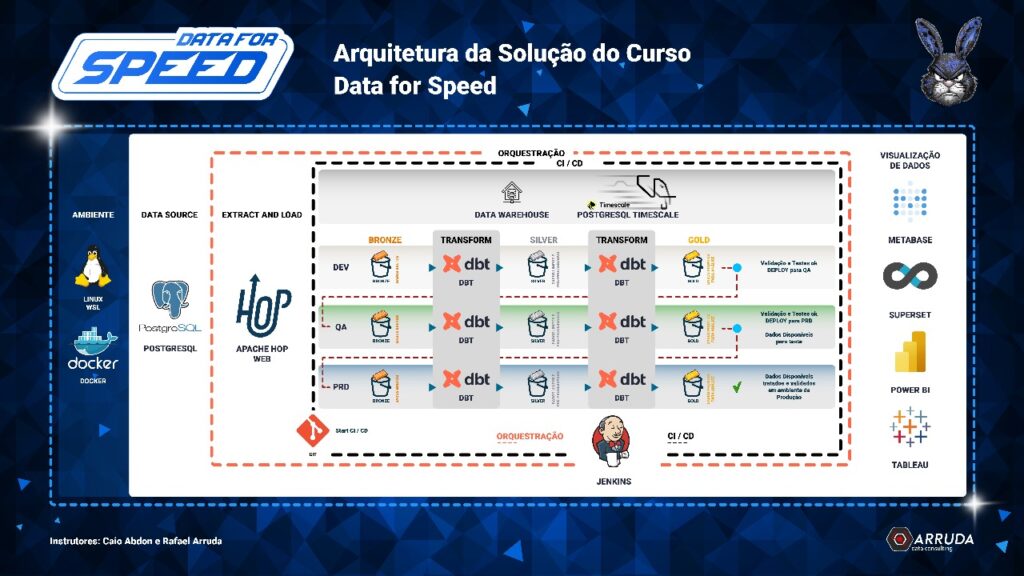
Então na Arquitetura acima temos as seguintes tecnologias:
- Toda Stack em Containers.
- Apache Hop Para ingestão dos dados.
- DBT para Transformação e validação dos dados.
- Postgres para DW.
- Jenkins como CI/CD e Orquestração.
Agora imagine o seguinte cenário: seu gerente prefere uma solução em nuvem. Em vez de armazenar os dados no PostgreSQL, você os coloca no armazenamento da cloud escolhida.
Se for Google Cloud, usamos o Hop para gravar no Cloud Storage e o dbt atua sobre o BigQuery.
Se for AWS, gravamos no S3 e podemos usar Athena ou Redshift.
Se for Snowflake ou Databricks, a stack continua a mesma — já que ambas se integram nativamente com os storages das três principais clouds.
Todo o restante da Stack não mudaria.
Exemplo prático com AWS
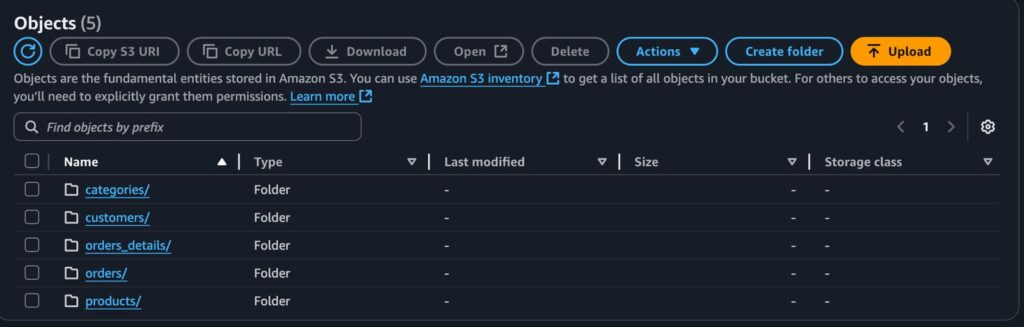
Para começar, usamos o Apache Hop para ler dados de um banco PostgreSQL e gravá-los no S3, em formato Parquet.
Cada tabela possui sua respectiva pasta e arquivos:
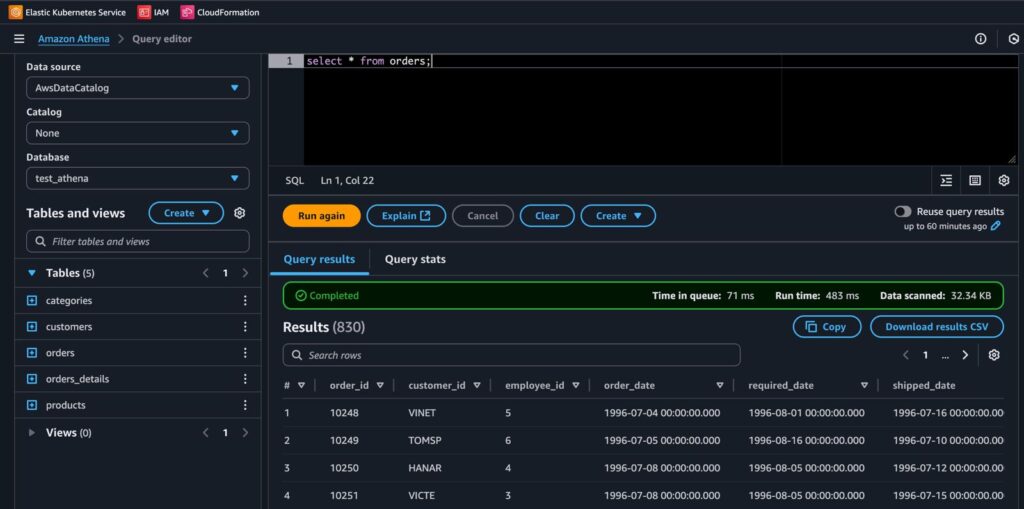
Com os dados no S3, agora já conseguimos consultá-los usando o Athena, que é um serviço serverless da AWS que permite consultas SQL diretamente sobre arquivos no S3.
Tanto Athena quanto Redshift possuem integração nativa com dbt.
Veja abaixo os dados sendo consultados no Athena:
Conclusão
Em vez de utilizar o PostgreSQL, conseguimos criar um Data Lake na AWS, mantendo exatamente a mesma stack do Data Speed.
A grande vantagem é que nos preocupamos apenas com o processamento. O armazenamento e a consulta são administrados pela AWS.
E o que mais encarece um projeto na nuvem geralmente é o processamento contínuo. Neste caso, você só paga pelo que rodar — e se estiver usando máquinas locais, nem esse custo terá.
Muito Obrigado.
Rafael Arruda