Neste artigo, vamos falar sobre a ferramenta dbt (Data Build Tool), focando especificamente na realização de cargas incrementais em nossos modelos.
Ao criarmos um modelo e realizarmos a primeira carga de dados, pode não ser vantajoso executar uma carga completa (full load) a cada atualização, especialmente em projetos com grande volume de dados. É justamente nesse ponto que o modo incremental do dbt se torna extremamente útil.
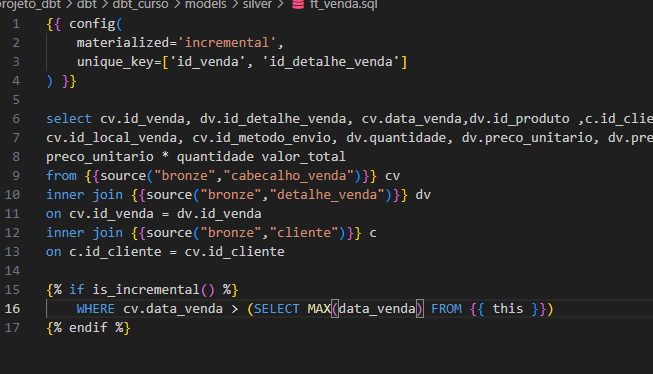
Como exemplo, vamos considerar o SELECT que gera a tabela ft_venda. Inicialmente, ela estaria configurada para realizar uma carga completa dos dados. Porém, se adicionarmos no início do nosso arquivo .sql a instrução:
{{ config(
materialized=’incremental’,
unique_key=[‘id_venda’, ‘id_detalhe_venda’]
) }}
E incluirmos ao final do SELECT uma cláusula de filtro para capturar apenas os dados novos, como:
{% if is_incremental() %}
WHERE cv.data_venda > (SELECT MAX(data_venda) FROM {{ this }})
{% endif %}
Então o dbt será capaz de identificar e atualizar apenas os registros mais recentes, tornando o processo de carga muito mais eficiente.

Vamos entender melhor o que esses comandos fazem.
Quando definimos no início do arquivo a configuração materialized=’incremental’, estamos informando ao dbt que, no final do script, haverá uma cláusula WHERE responsável por filtrar apenas os dados novos ou alterados. Essa filtragem pode ser ignorada caso optemos por realizar uma carga completa (full refresh), utilizando o parâmetro –full-refresh no comando de execução.
A configuração unique_key é utilizada para definir a chave que o dbt deve considerar ao realizar atualizações (updates). Ou seja, o dbt será capaz tanto de inserir novos registros que ainda não existem no nosso Data Warehouse quanto de atualizar registros já existentes, conforme a chave especificada.
Já o comando {{ this }} é uma referência dinâmica ao modelo atual que está sendo executado. No exemplo dado, ao utilizarmos (SELECT MAX(data_venda) FROM {{ this }}), estamos pedindo ao dbt para buscar a data máxima da tabela destino (o próprio modelo), garantindo que apenas dados mais recentes sejam processados na próxima execução incremental.
Para finalizar, podemos verificar na pasta target, no arquivo run_results.json, se a nossa carga incremental foi realizada corretamente.
No meu caso, a tabela original possuía cerca de 120 mil linhas, e o modelo incremental precisava apenas selecionar as 96 novas linhas e realizar a inserção. É exatamente isso que o arquivo run_results.json nos mostra: a confirmação de que apenas as novas linhas foram processadas e inseridas com sucesso.

Sendo assim, podemos observar a capacidade do dbt de realizar não apenas inserções, mas também atualizações durante nossas cargas de dados, evidenciando o poder e a eficiência dessa ferramenta na construção de pipelines de dados modernos e escaláveis.
Muito Obrigado.
Até o próximo artigo.