Neste artigo, vamos falar sobre a ferramenta dbt (Data Build Tool) e por que ela vem se tornando cada vez mais requisitada em ecossistemas de dados modernos, como Snowflake, BigQuery, Redshift, entre outros.
Ao utilizarmos uma infraestrutura de dados moderna, é comum realizarmos diversas transformações por meio de SQL, aproveitando a alta performance dos bancos de dados mencionados. No entanto, à medida que o projeto cresce, torna-se difícil manter o controle dos scripts, mesmo com os recursos nativos dessas plataformas. Além disso, a documentação dessas transformações tende a ser negligenciada ou difícil de manter, o que pode comprometer a governança e a escalabilidade do projeto.
Ao iniciarmos um projeto no dbt, temos a pasta models, onde podemos criar várias subpastas para organizar nossos modelos SQL. Essa estrutura modular facilita a manutenção e leitura do código, especialmente em projetos maiores com múltiplas áreas de negócio ou etapas de transformação.
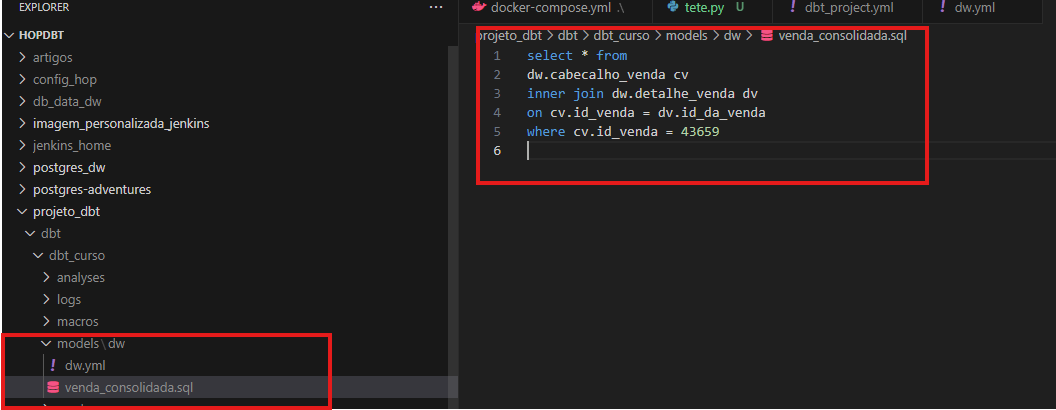
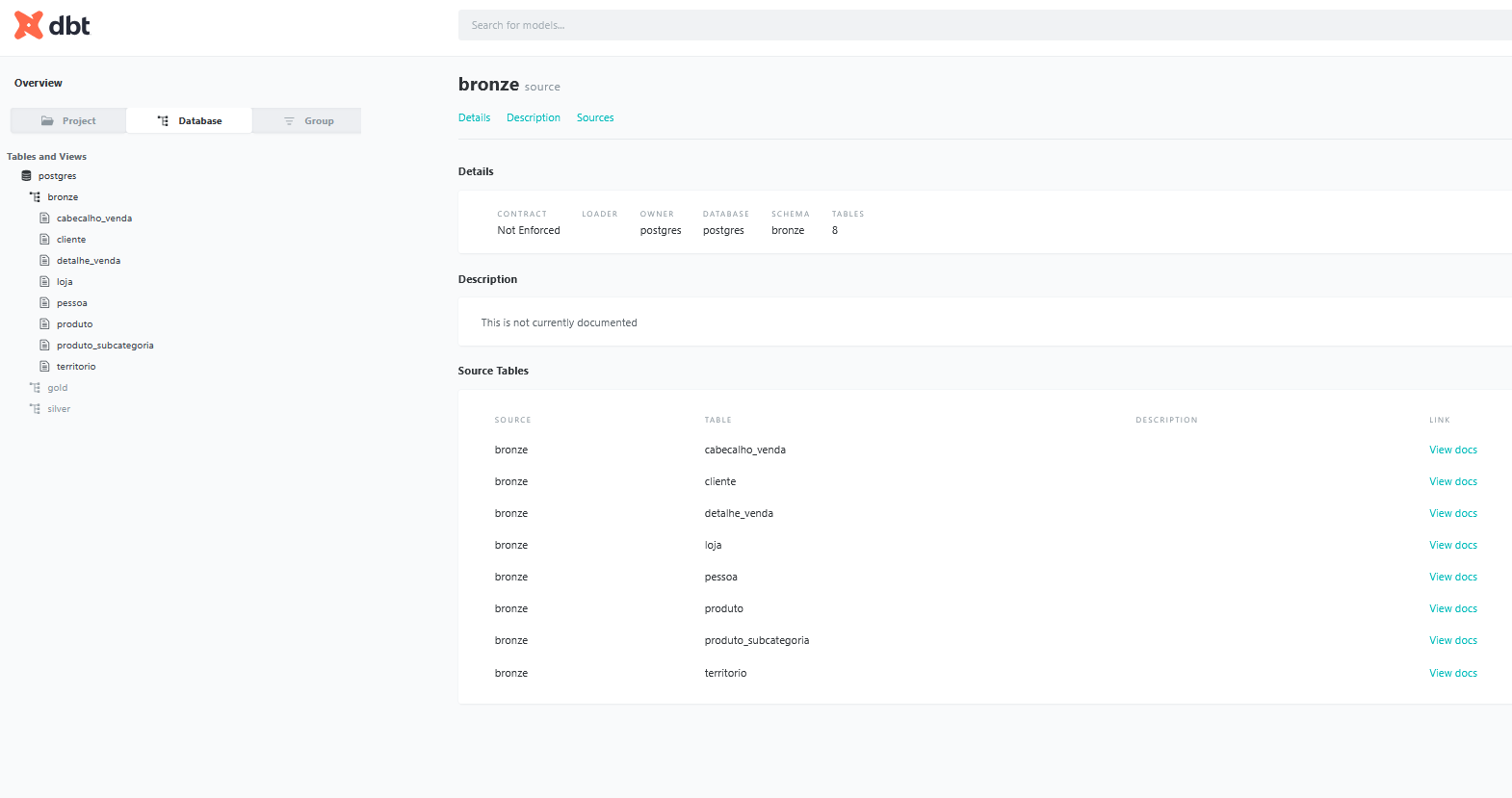
Após termos nosso modelo desenvolvido, podemos começar a realizar a documentação do mesmo, e a melhor parte? A documentação fica na mesma pasta do model, em um arquivo .yml, no exemplo acima, fica no arquivo de dw.yml.
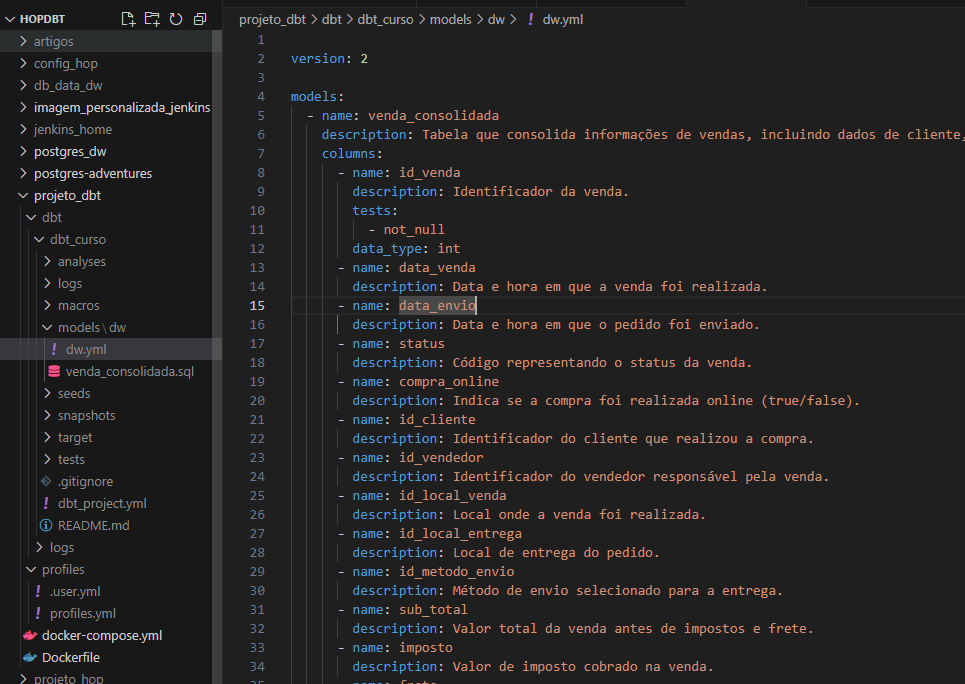
Como podemos ver neste arquivo, estou definindo o nome e a descrição da tabela, além de documentar o nome e a descrição de cada coluna. Também estou adicionando alguns testes de dados — como, por exemplo, na coluna id_venda — para garantir que os dados tenham o tipo e o retorno esperados durante a transformação.
Além disso, o dbt permite configurar múltiplas conexões no arquivo profiles.yml, conhecidas como targets. Isso significa que, com a adição de uma simples flag no comando de execução, é possível alternar o ambiente onde o script será executado, como entre produção, homologação ou desenvolvimento.
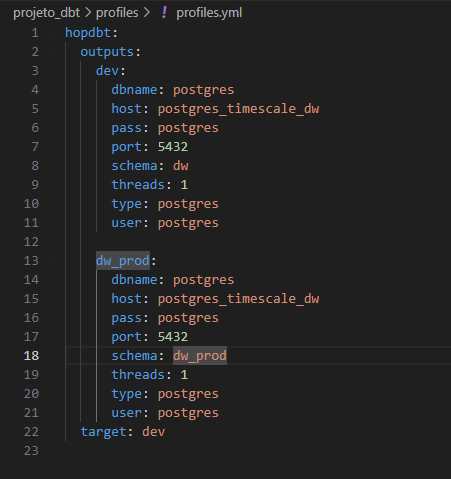
Se alterarmos o comando de execução de dbt run para dbt run –target dw_prod, o dbt utilizará a nova conexão definida no profiles.yml, criando automaticamente o schema correspondente (caso ainda não exista) e executando as transformações, incluindo a criação das tabelas no novo destino.
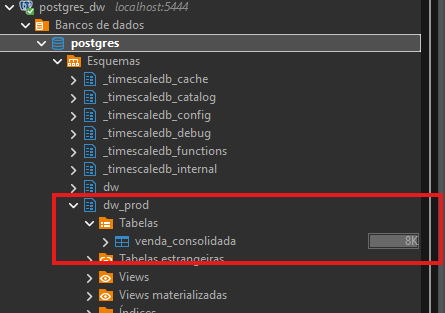
Isso nos permite separar ambientes como dev, homologação e produção, garantindo maior controle e segurança durante o ciclo de desenvolvimento. Além disso, como o dbt organiza as transformações em arquivos SQL dentro de um projeto estruturado, podemos versioná-lo em plataformas como GitHub ou GitLab.
Isso facilita o trabalho colaborativo entre desenvolvedores, promovendo revisões de código, controle de mudanças e aumento significativo da produtividade da equipe.
Ao finalizar o ciclo de desenvolvimento, podemos rodar o comando dbt docs generate, onde o dbt vai gerar a documentação do projeto com base nas nossas configurações. Logo depois, podemos usar o comando dbt docs serve, onde essa documentação vai ficar disponível pela porta 8080 (padrão) do navegador, podendo alterar a porta com o comando –port para não ter conflito com demais aplicações.
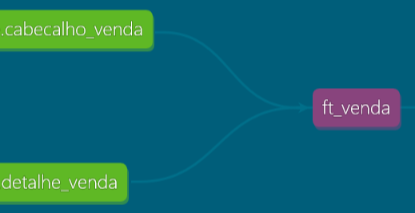
Também podemos ver a linhagem dos dados, para saber quais tabelas foram utilizadas para gerar a de destino como mostra na imagem abaixo.
Dessa forma, temos um projeto documentado e colaborativo.
Muito Obrigado.
Time Arruda Consulting