
Neste post compartilho com vocês duas maneiras de criar Loop utilizando o Apache Hop.
Objetivo:
Criar 2 modelos de loop que percorra uma pasta principal, acesse todas as subpastas dentro dela, e leia todos os arquivos XLSX encontrados em cada subpasta. O loop funcionará independe do número de subpastas que haja na pasta principal.
Neste exemplo eu crie uma pasta chamada Loops, uma subpasta chamada Empresas e dentro desta subpasta criei mais 3 subpastas (Empresa A, Empresa B, Empresa C).
Dentro de cada uma destas subpastas há o arquivo cliente.xls que será lido pelo loop que iremos implementar.

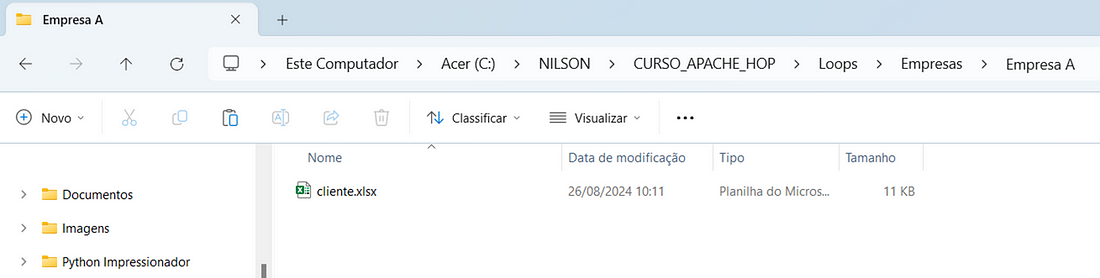
Formato do arquivo excel que será lido
Modelo de Loop 1 — Usando copy rows to result
PASSO 1: Criar uma transform Get subfolder names que irá pegar o nome das subpastas de uma determinada pasta.
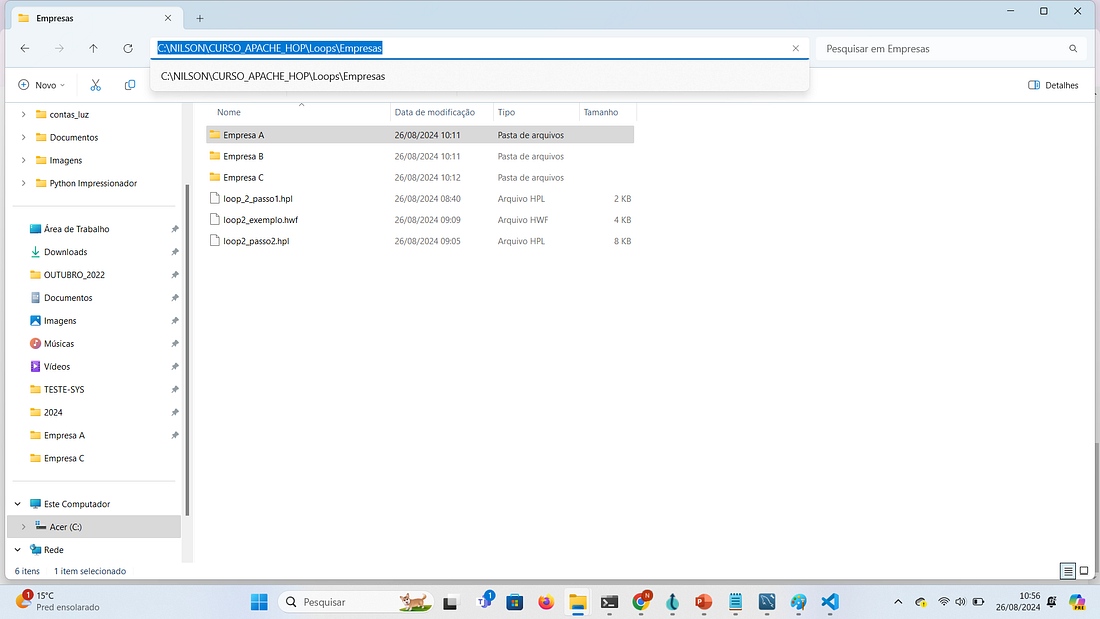
Edite a transform e determine no campo Directory qual é o diretório raiz onde você obterá as informações. No nosso exemplo esse é o caminho:
C:\NILSON\CURSO_APACHE_HOP\Loops\Empresas
Após selecionar o diretório clique em !GetSubFoldersDialog… e depois em Preview Rows para visualizar as pastas
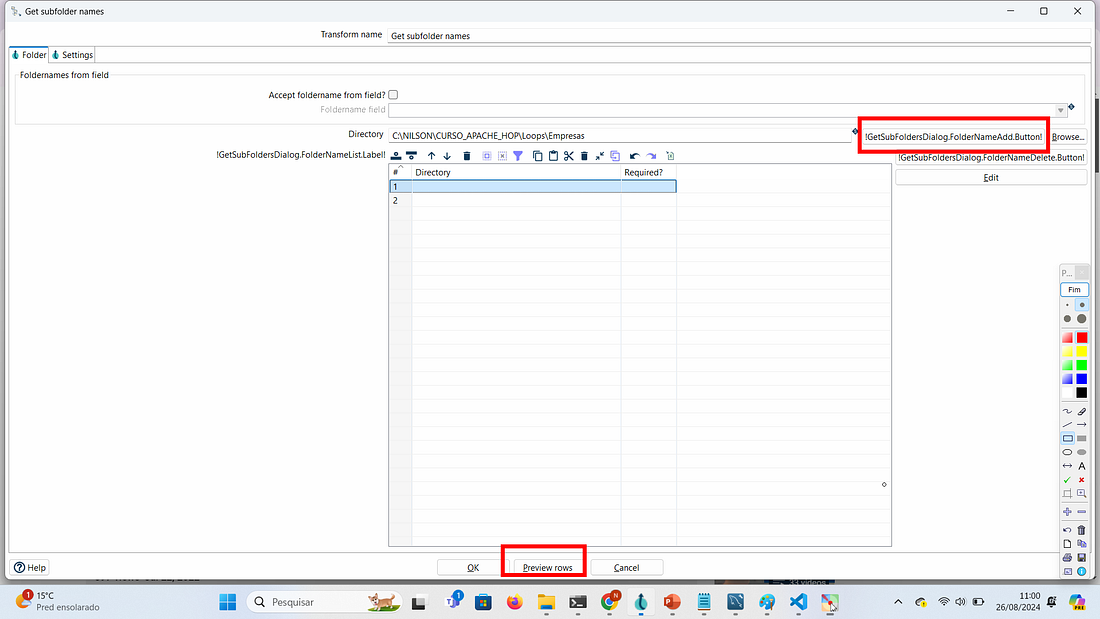

As informações listadas serão encaminhadas para um novo pipeline, onde cada linha processada executará uma tarefa específica, criando um loop automático para cada linha da planilha. A próxima transform Copy rows to result será responsável por gerenciar esse processo.
PASSO 2: Criar a transform Copy rows to result e ligar com a transform Get subfolder names e na sequencia editá-la.
Todo o pipeline de dados será passado para essa transform como resultado, permitindo a execução do próximo pipeline.
Execute a pipeline para testar se não erro.

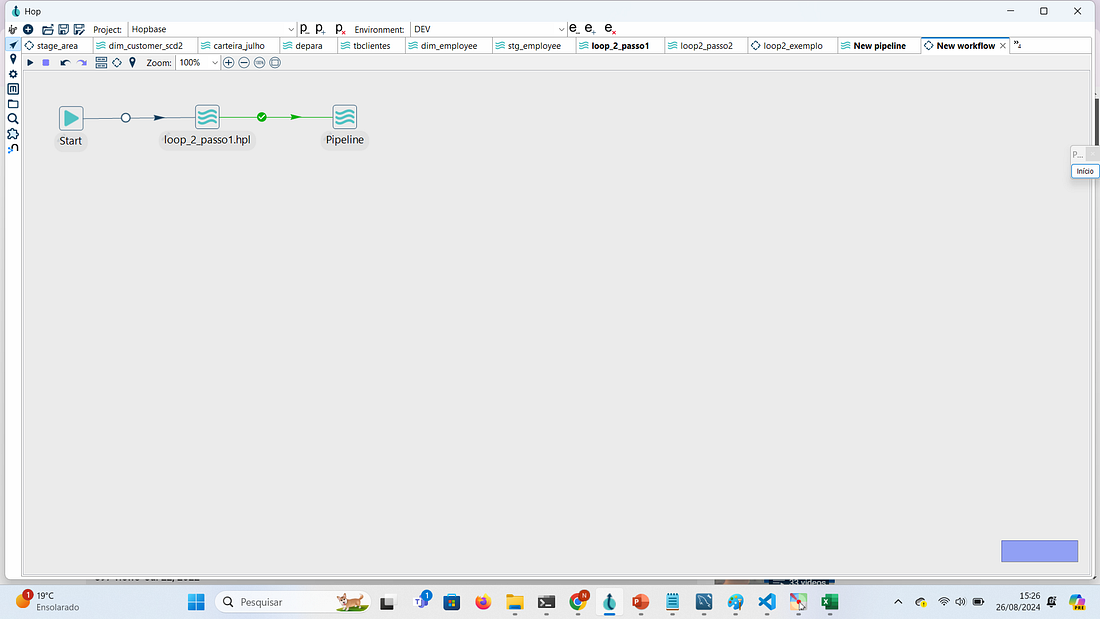
Salvaremos essa pipeline com o nome de loop_2_passo1

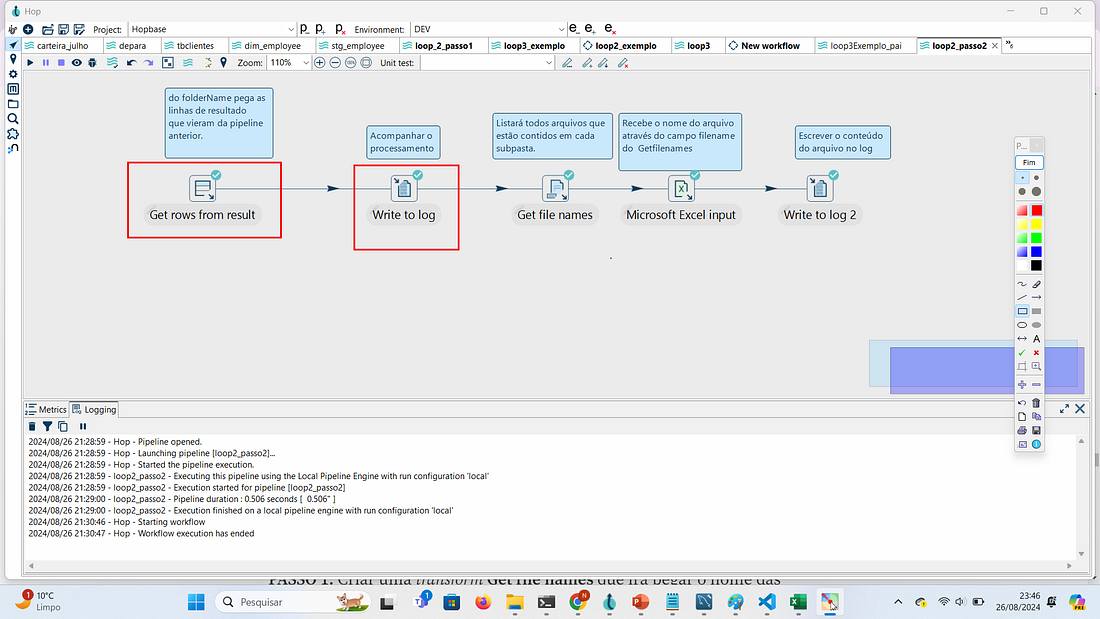
PASSO 3: Criar uma nova pipeline incluindo a transform Get rows from result. Ela servirá para pegar as linha de resultado que vieram da pipeline anterior loop_2_passo1.
Edite a transform e defina quais são as informações que será aproveitada da pipeline.
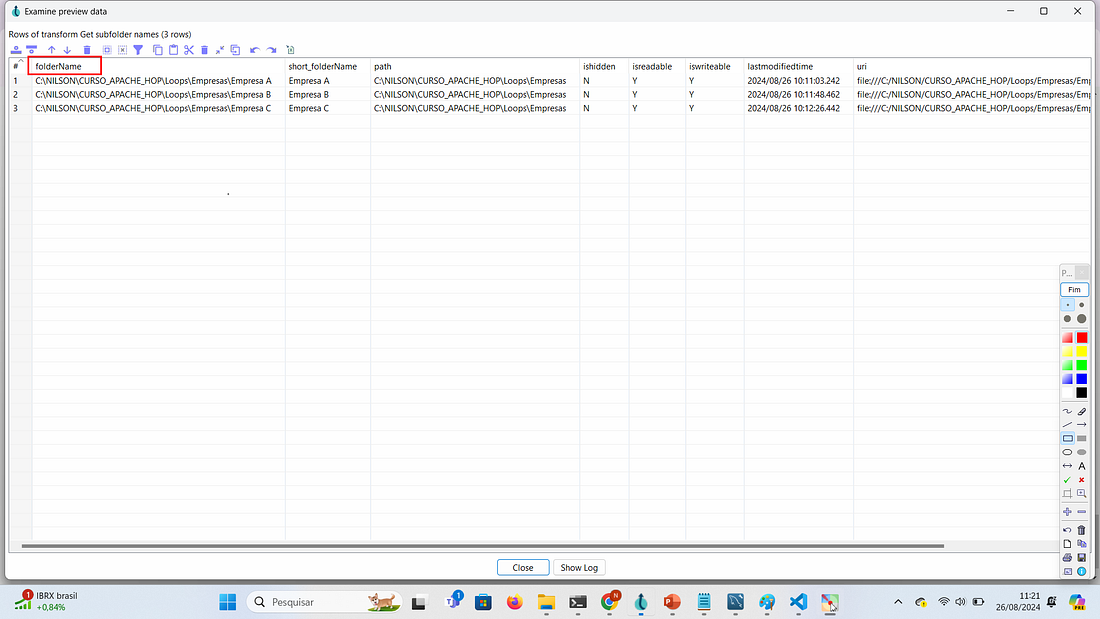
Neste exemplo, utilizaremos o campo folderName, que contém o caminho completo da pasta que desejamos ler. Dentro dessa pasta, pode haver muitos arquivos. Essa informação é obtida ao realizar um preview na transformação Get subfolder names da pipeline loop_2_passo1, que será então passada para a nova pipeline.
Incluir em Fieldname o folderName e em Type como String.
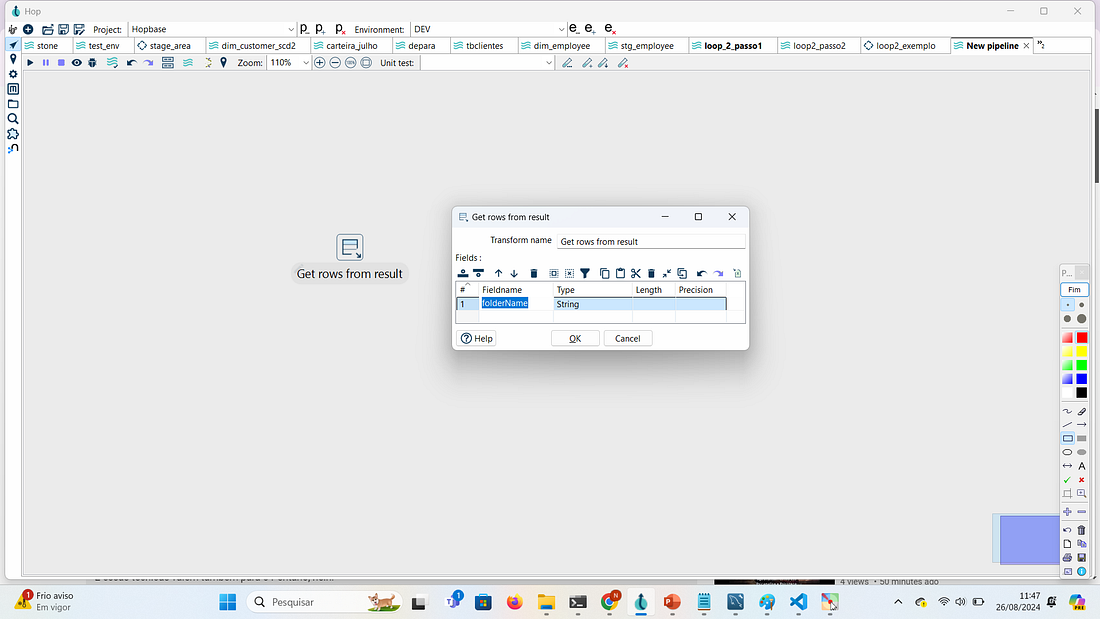
Assim que obtida, essa informação ela será passada para o próximo step.
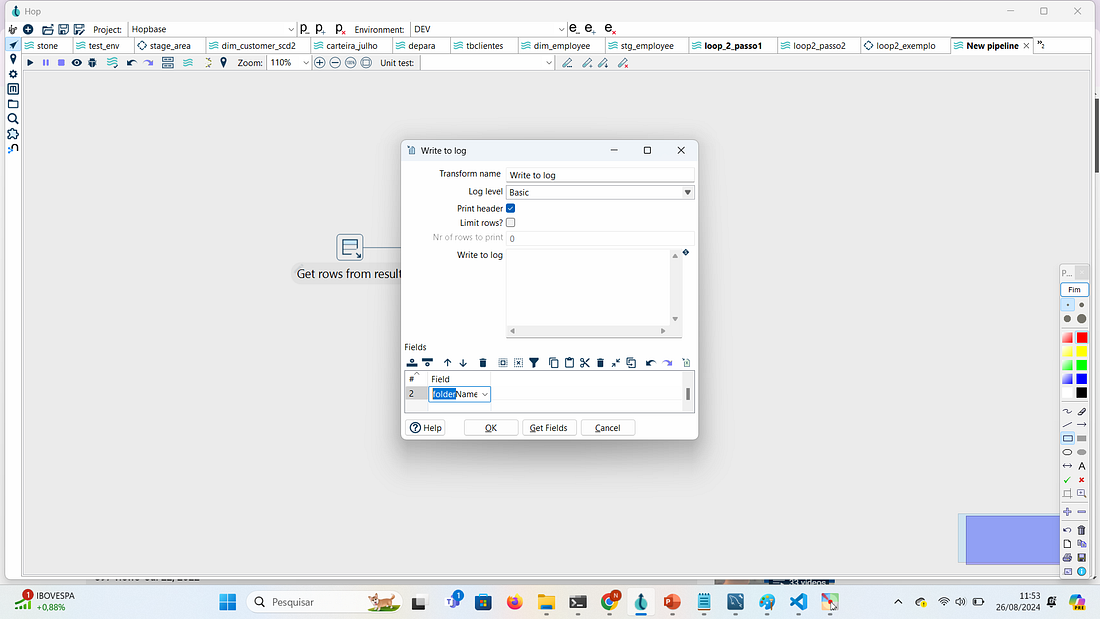
PASSO 4: Criar uma transform Write to log para acompanhar o processamento que será feito e ligá-la a transform anterior Get rows from result.

Definir no campo Field o campo folderName
PASSO 5: Criar uma transform Get file names e ligar a transform anterior. Essa transform entrará em cada pasta, listará e processará os arquivos contidos nela.

Edite a transform e marque o campo Is filename defined in a field? e em Get filename from field selecione folderName

PASSO 6: Criar uma transform Microsoft Excel Input para receber essas informações.
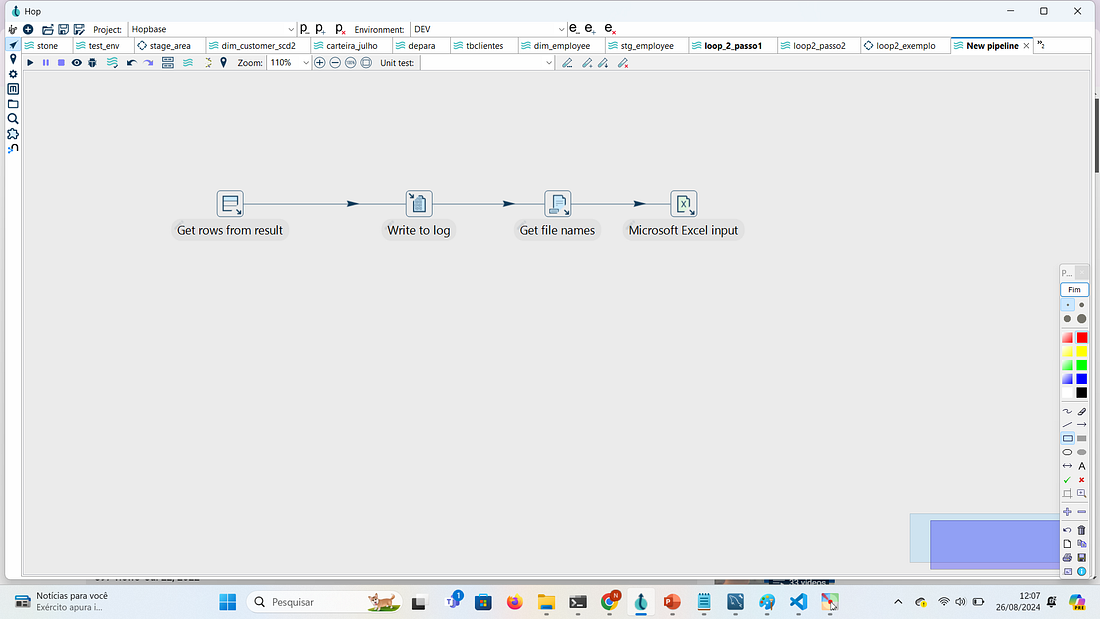
Edite a transform e em Spread sheet type (engine) marcar que o tipo do arquivo. Neste nosso exemplo os arquivos são xlsx.
1 — Marcar o item Accept filenames from previous transform
2 — Em Transform to read filenames from selecionar Get file names, para indicar que ele recebe o nome do arquivo através do step Get file names
3 — Em Field in the input to use as filename selecionar filename, que foi o nome do campo definido no step Get file names.
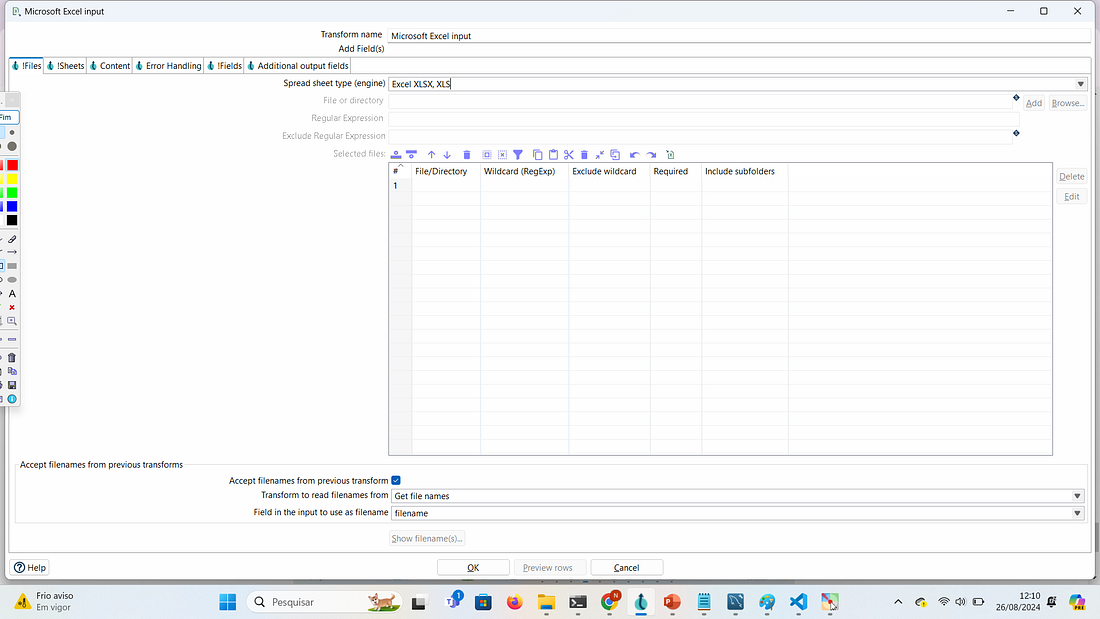
Selecione a aba Sheets e inclua o nome da aba do arquivo que será lido. Em Em nosso exemplo o nome da aba do nosso arquivo cliente.xlsx é Plan 1.
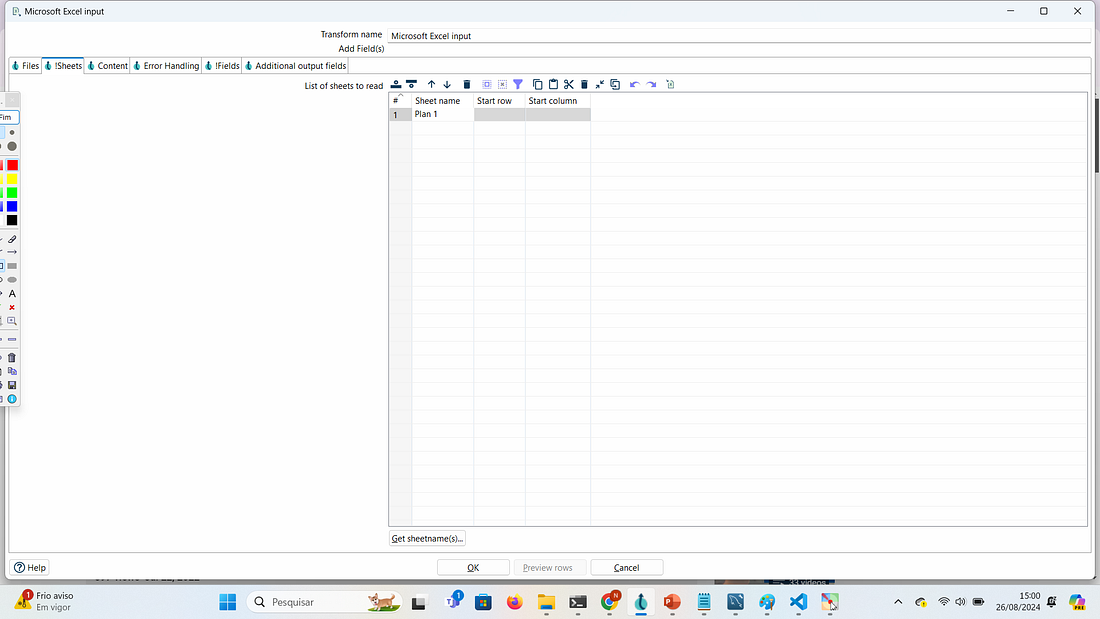
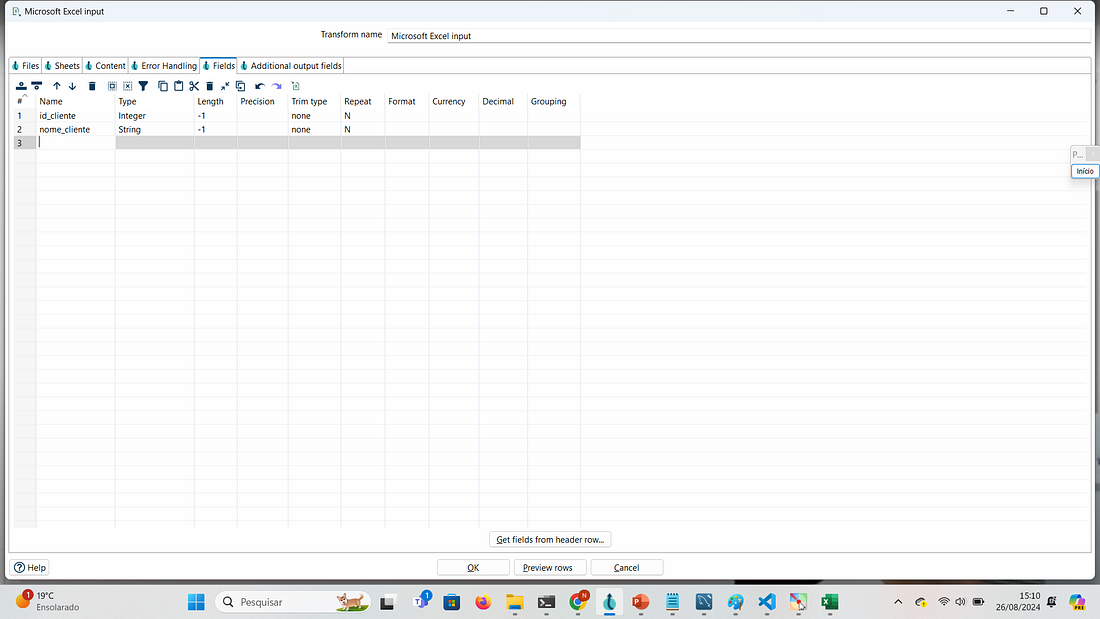
Selecione a aba Fields e inclua a estrutura do arquivo excel. Em nosso exemplo temos apenas duas colunas id_cliente e nome_cliente no arquivo cliente.xlsx.
PASSO 7: Criar uma nova transform Write to log para escrever o conteúdo do arquivo no log.

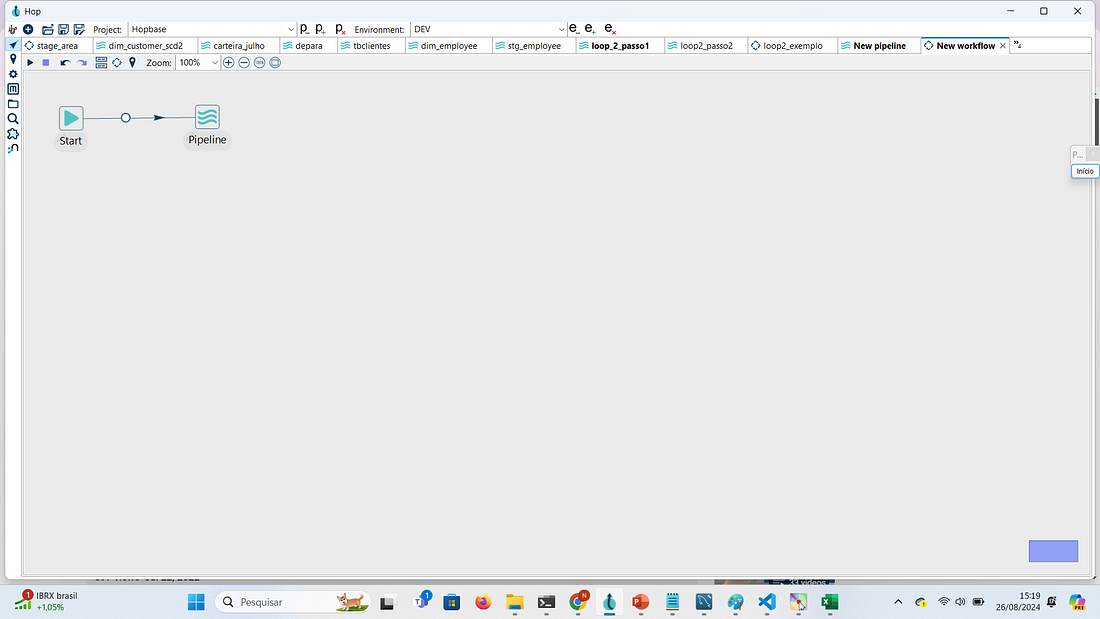
PASSO 8: Criar um workflow para permitir que o pipeline loop_2_passo1 passe informação para o pipeline loop_2_passo2.
Ligar a action Start à action Pipeline
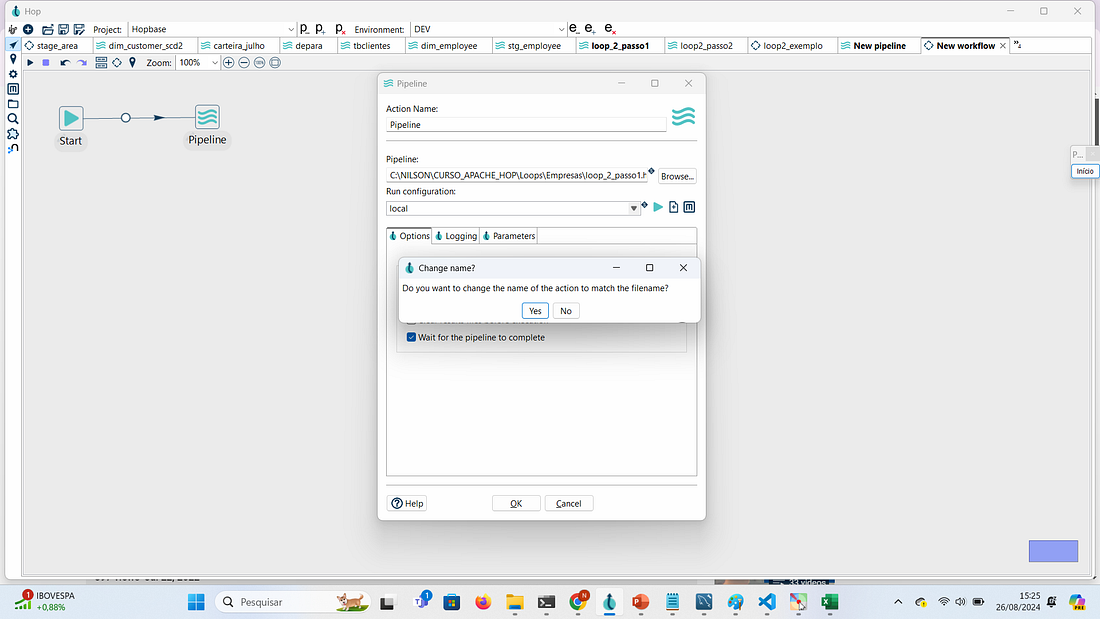
Editar a pipeline e clicar no botão Browser em Pipeline: e selecionar o loop_2_passo1 e clicar em Yes.
PASSO 9: Agora criaremos uma nova pipeline repetindo o procedimento acima para o loop_2_passo2.
Editar a pipeline e clicar no botão Browser em Pipeline: e selecionar o loop_2_passo2 .
Importante marcar o item Execute for every result row para que seja executado em forma de loop executando o conteúdo do arquivo linha a linha. Por fim clique no botão OK e salve o workflow como loop2_exemplo.
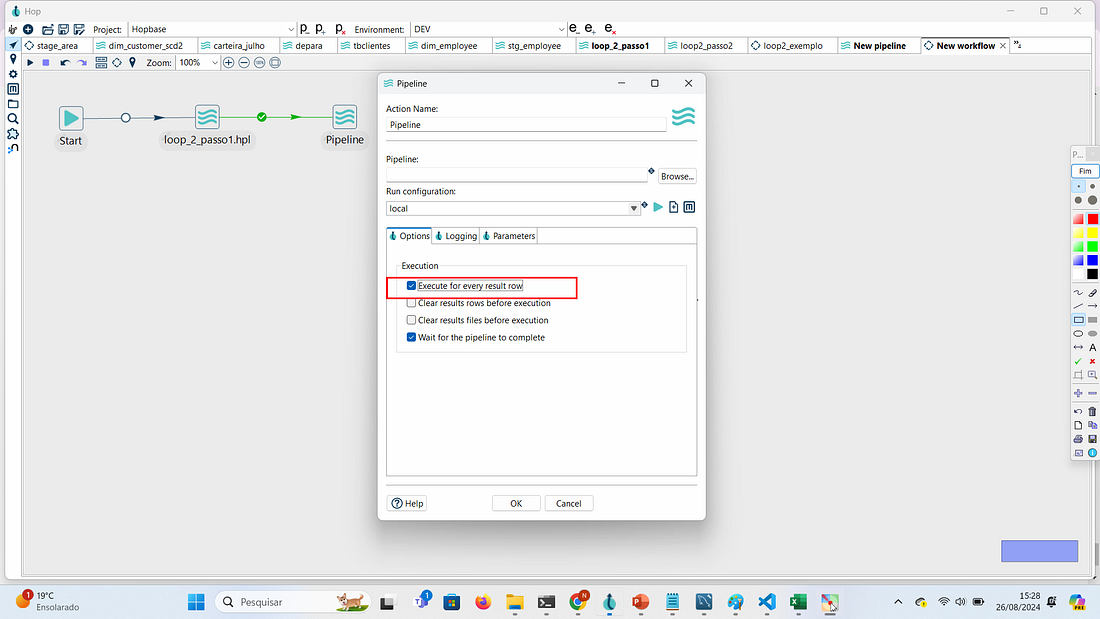
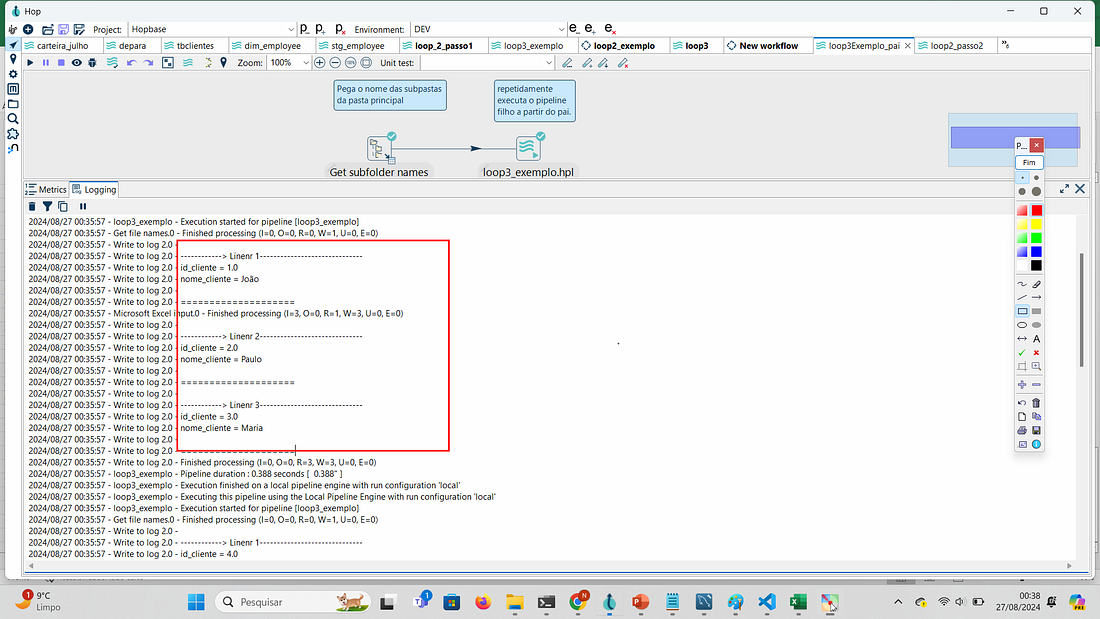
PASSO 10: Clique em Executar para executar os dois pipelines e ver o resultado no log. Note pelo log que o processo leu a pasta principal, listou as subpastas e dentro de cada subpasta leu os dados do arquivo cliente.xlsx.
Loop na Empresa A

Loop na Empresa B
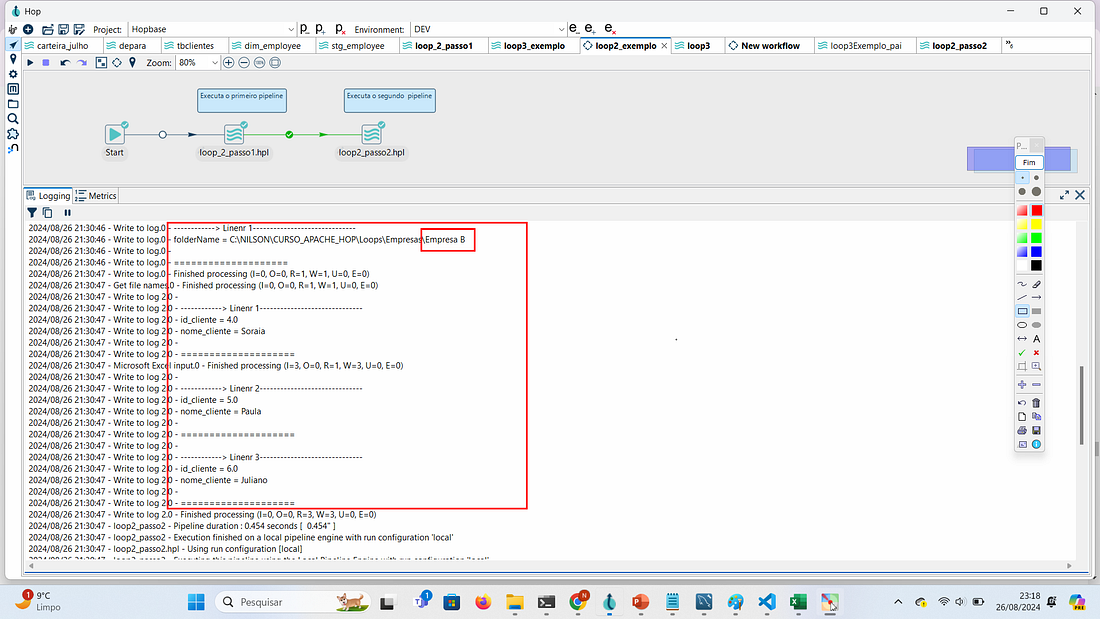
Loop na Empresa C

Modelo de Loop 2 — Pipeline Executor
Para esse modelo iremos aproveitar a pipeline loop_2_passo2, iremos salvá-la com um novo nome loop3_exemplo.
PASSO 1: Excluir os steps Get rows from result e Write to log, que não serão necessários.
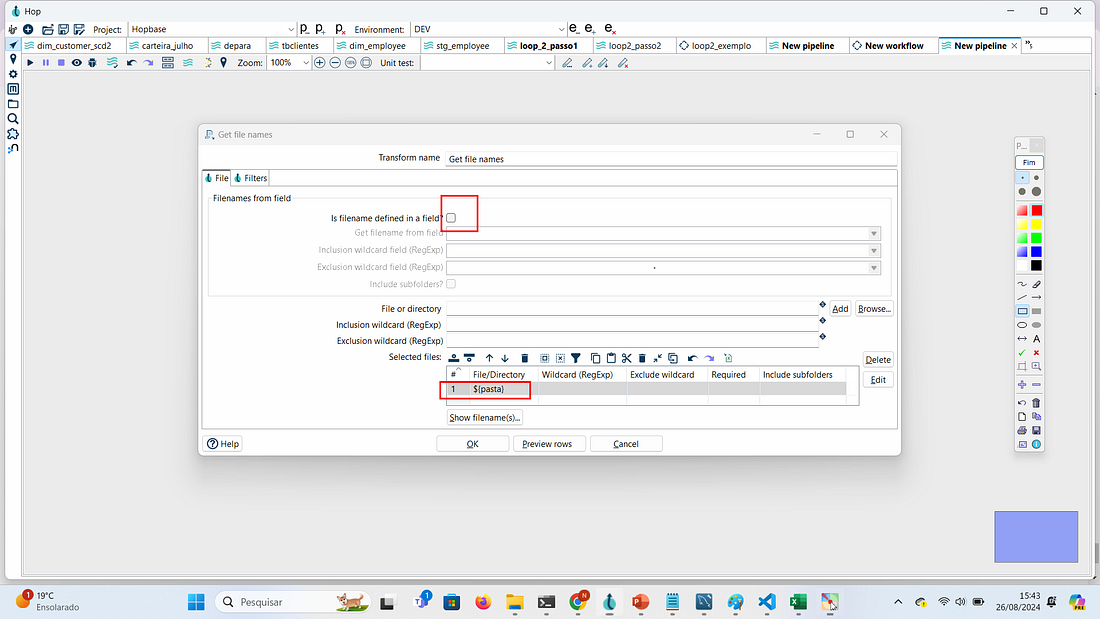
PASSO 2: Editar a transform Get file names que irá pegar o nome das subpastas de uma determinada pasta e editar

Desabilitar o Is filename defined in a field para que a seja habilitada o Select files, para incluir a variável ${pasta}
Essa variável pasta será preenchida dinamicamente com no nome da pasta que contém o arquivo. O Get file names ficará encarregado de listar o arquivo e passar para a próxima transform.
PASSO 3: Criar uma nova pipeline e criar a transform Get subfolder names para pegar o nome da pasta que queremos.

editar a transform e copiar o caminho da pasta principal onde estão subpastas.

PASSO 4: Perceba que neste modelo de loop 2, eu não jogarei o resultado do step anterior em um step Copy rows to result, mas em um pipeline executor.
Criar uma transform Pipeline Executor para pegar o nome da pasta que queremos.
Neste exemplo o resultado irá para um pipeline executor
Para cada linha que for processado na pipeline principal também será executada a pipeline executor, ou seja, o loop será feito até o final do arquivo.
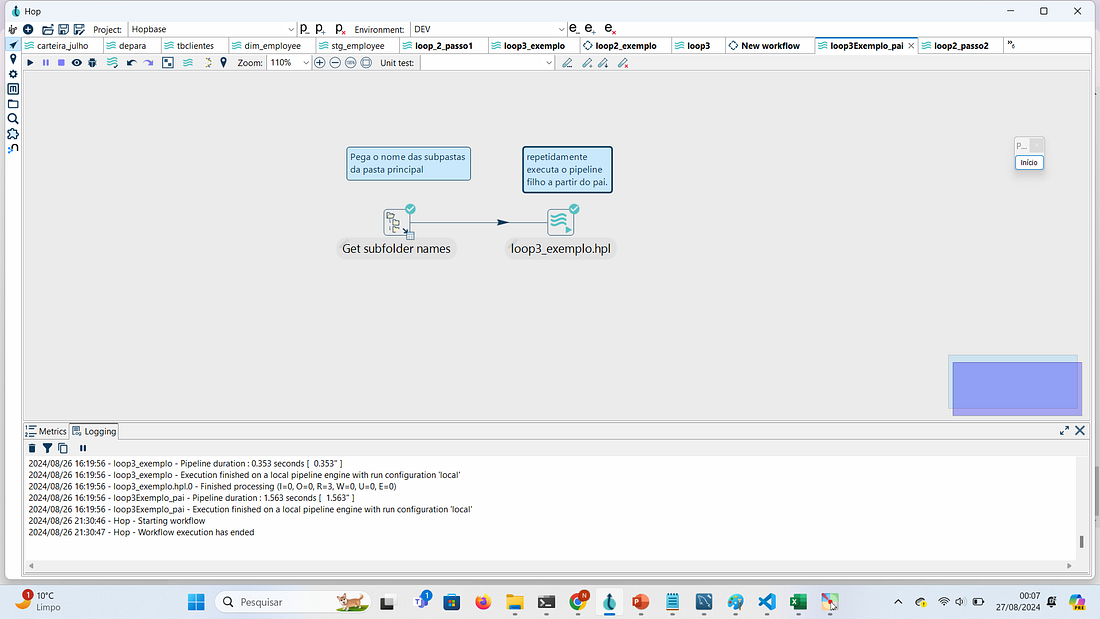
Editar a pipeline executor e clicar em Browser e pesquisar a pipeline loop3_exemplo.hpl
Definir Variable / Parameter name como “pasta” e em Field to use selecionar folderName e clicar em OK. Desta maneira o conteúdo do folderName será passado para a variável pasta.

Salve essa pipeline com o nome loop3Exemplo_pai
Passo 5: Execute o pipeline e acompanhe resultado pelo log.

Conclusão
Mostrei neste tutorial duas maneiras de fazer loop, utilizando o Apache Hop, sendo a última solução a mais performática.
Soluções estas que também se adaptam ao Pentaho.
Muito Obrigado.
Nilson Braga
Gostou deste post? Conecte-se comigo no linkedin