Bom, na semana passada tivemos mais uma Live dos Sparkanos, e dessa vez com um Hand-ons de 2 horas de Apache Spark.
E uma das dúvidas que surgiram, foi entender como o cliente acessa esses dados, uma vez que processamos os dados com o Spark.
Para facilitar o entendimento vou deixar um tutorial abaixo desde a ingestão dos dados na camada bronze utilizando o Jupyter Notebook e como acessar os dados via Trino.
Então neste exemplo iremos acessar os dados de duas maneiras:
- Jupyter utilizando Pyspark.
- Trino utilizando Querys SQL.
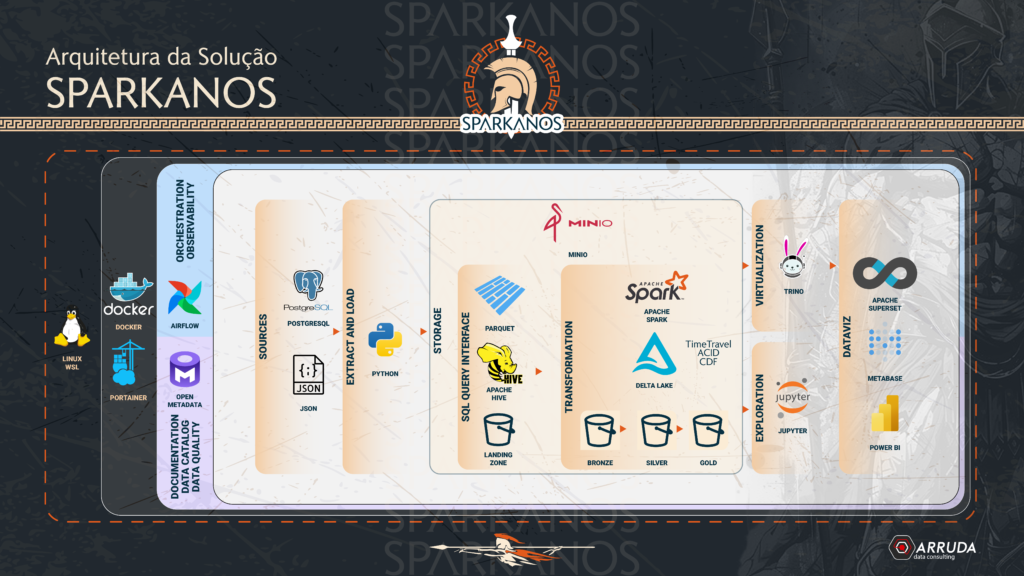
Na nossa Arquitetura acima, temos as nossas camadas bronze, silver e gold armezando todos os nossos dados em formato Delta, aproveitando toda a integração entre Spark & Delta, como por exemplo:
- Time Travel.
- ACID.
- CDF.
Bom vamos lá…
Ao criar um novo Notebook iremos começar pelas configurações do Spark e também do Minio que é aonde armazenamos os nossos dados neste projeto dos Sparkanos.
import pyspark
from pyspark.sql import SparkSession
import logging
spark = SparkSession.builder \
.appName("ELT Full Postgres to Landing AdventureWorks") \
.config("spark.hadoop.fs.s3a.endpoint", "http://minio:9000") \
.config("spark.hadoop.fs.s3a.access.key", "chapolin") \
.config("spark.hadoop.fs.s3a.secret.key", "mudar@123") \
.config("spark.hadoop.fs.s3a.path.style.access", True) \
.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \
.config("spark.hadoop.fs.s3a.aws.credentials.provider", "org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider") \
.config("hive.metastore.uris", "thrift://metastore:9083") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
Agora iremos ler os dados do Minio
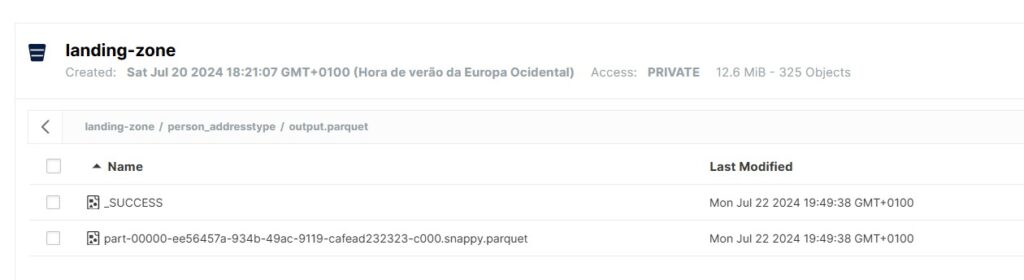
E aqui começamos a ler os dados no Jupyter.
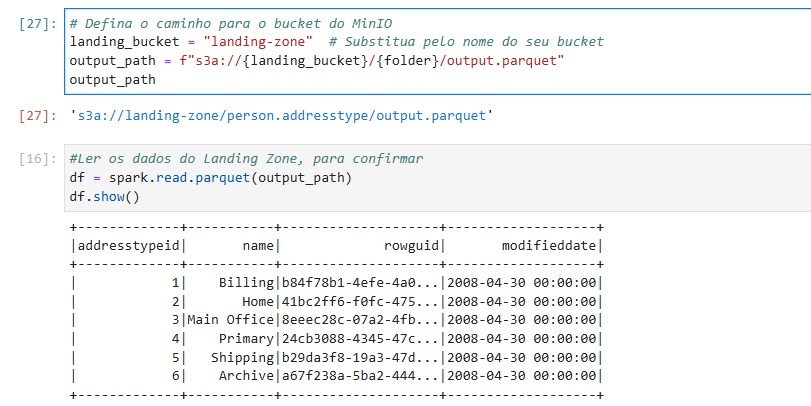
Agora iremos gravar os dados desta tabela na camada bronze
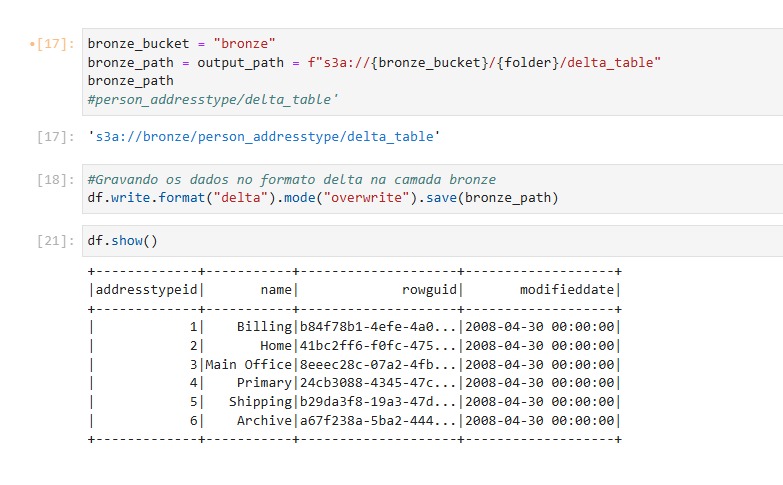
Ingestão dos dados feita com sucesso na camada bronze
Agora iremos acessar esses dados via SQL utilizando o Trino, no Dbeaver.
E para acessarmos esses dados precisamos criar os metadados e depois mapear a nossa tabela com o diretório que se encontra os nossos dados:
Comandos SQL no Trino
— Criando os metadados no Hive
CREATE SCHEMA hive.bronze WITH (location=‘s3a://bronze/’)
CREATE SCHEMA hive.silver WITH (location=‘s3a://silver/’)
CREATE SCHEMA hive.gold WITH (location=‘s3a://gold/’)
— Criando a Tabela no Trino
call delta.system.register_table (
schema_name => ‘bronze’,
table_name => ‘person_address’,
table_location => ‘s3a://bronze/person_address/delta_table’
);
— Consultando a tabela person_addres.
select * from delta.bronze.person_address
E agora já conseguimos analisar os dados via SQL
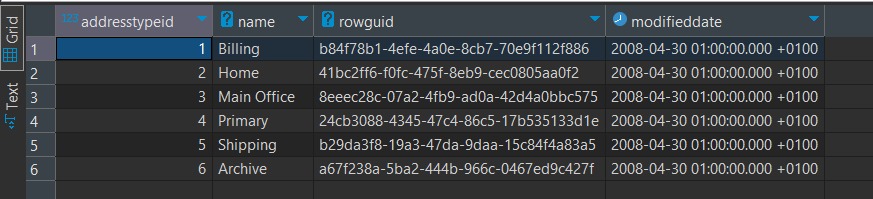
E aqui poderíamos fazer joins com outras tabelas, filtrar dados, agrupar dados basicamente utilizando SQL.
Então nessa arquitetura utilizamos o Spark para processamento dos dados, porém para analisar os dados podemos utilizar basicamente SQL.
E uma vez que os dados chegam no Trino, podemos conectar diversas Ferramentas de Dataviz como: Power BI, Tableau, Qlik e claro as versões Open Sources como Superset e Metabase.
Espero que este artigo tenha te ajudado a entender melhor a sequência e como integramos Spark, Minio e Trino para implementar um Pipeline de dados Robusto e altamente escalável.
Caso queira aprender mais sobre Apache Spark, recentemente fizemos uma Aula de 2 horas de Hand-ons.
Muito Obrigado e até o próximo Artigo.
Rafael Arruda