
Recentemente, explorei o uso do Apache Hop, uma poderosa ferramenta de ETL (Extração, Transformação e Carga) que facilita a automação e gestão de processos complexos de integração de dados.
Neste post, quero compartilhar um pouco sobre como o Apache Hop pode transformar seu processo de integração de dados, especialmente quando se trata de automatizar tarefas que exigem precisão e eficiência, como a extração de dados de fontes externas, por exemplo, APIs.
No exemplo fiz para um único CNPJ, mas daria também para ler os cnpjs de uma base SQL e iterar sobre eles.
PASSO 1: Criar uma transform Data Grid (ideal para criar conjuntos de dados estáticos para testes)
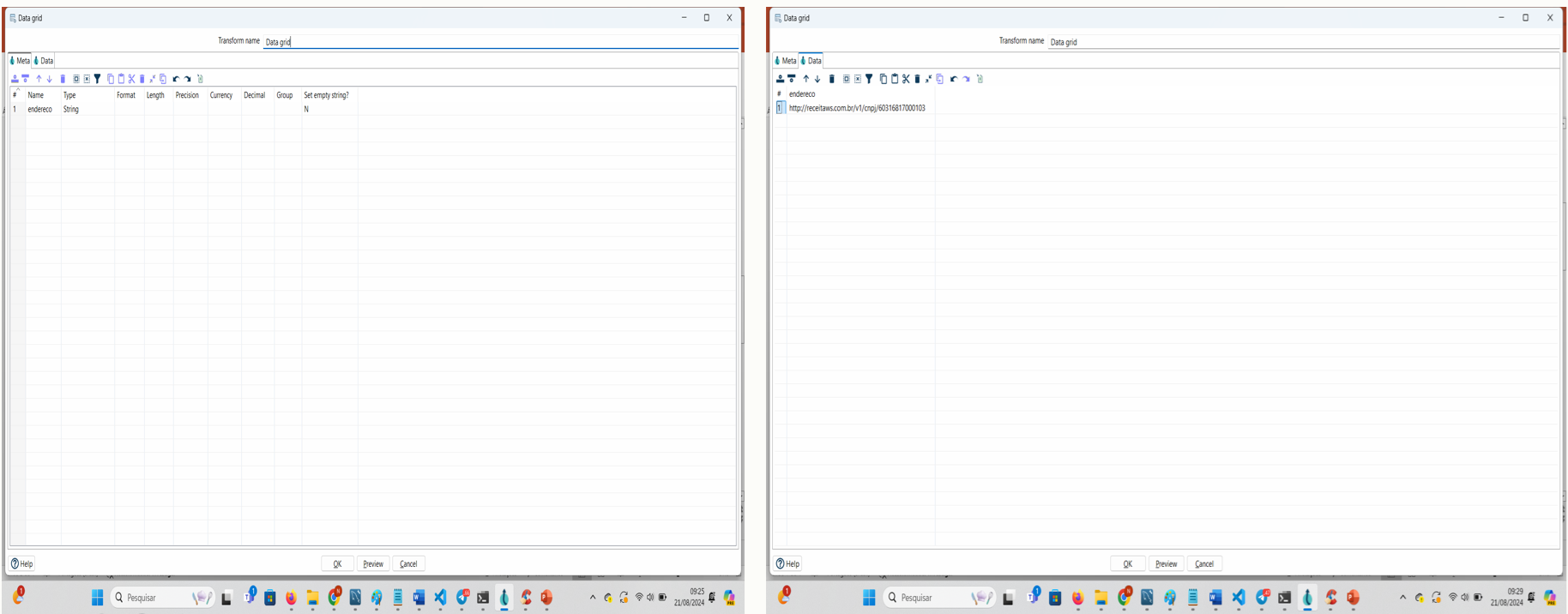
PASSO 2: Clique duas vezes para editar o Data Grid e na aba Meta incluir uma variável endereco. Na aba Data incluir a url da receita federal e um cnpj de consulta: http://receitaws.com.br/v1/cnpj/60316817000103
Documentação da API: https://developers.receitaws.com.br/#/operations/queryCNPJFree
Passo 3: Incluir uma transform Json Input e conectar a transform Data Grid na transform Json Input.
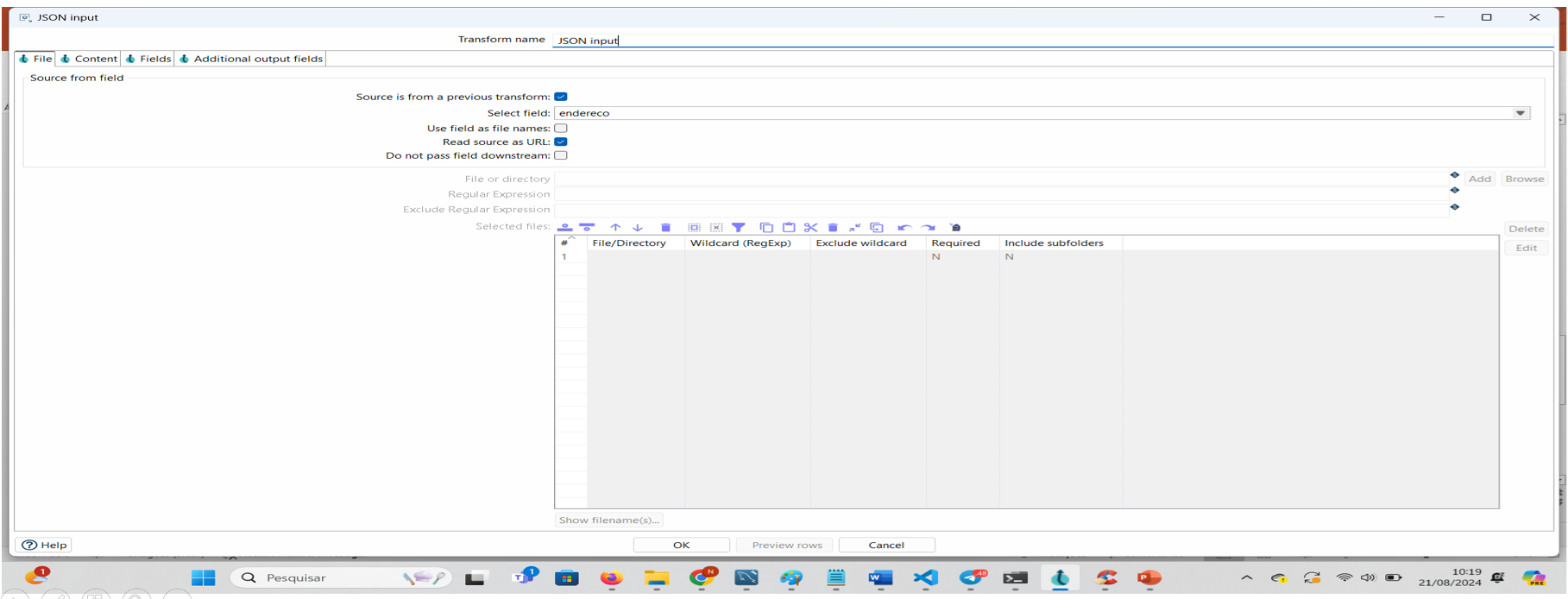
Passo 4: Clique 2 vezes para abrir a transform Json Input e marque a caixa source is from… para dizer a ele que a origem dos dados vem de uma transform anterior.
Em select Field selecione a variável endereco.
Em read source…, marca a caixa, indicando que o json será obtido da internet.
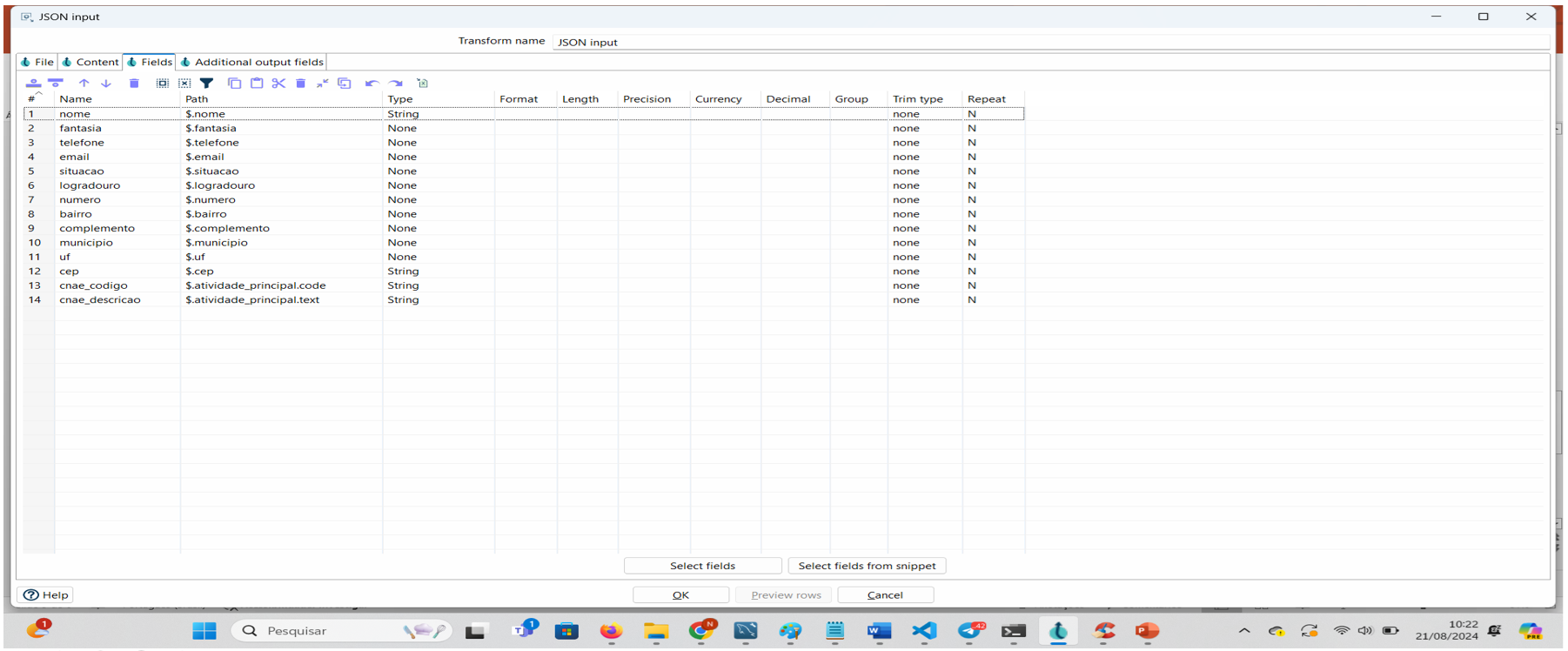
Passo 5: Na aba Fields incluir os campos que você quer capturar, presumindo que já olhou a documentação e conhece a estrutura do json.
Passo 6: Clique em Executar Pipeline ou Preview e veja os dados do cnpj capturado.
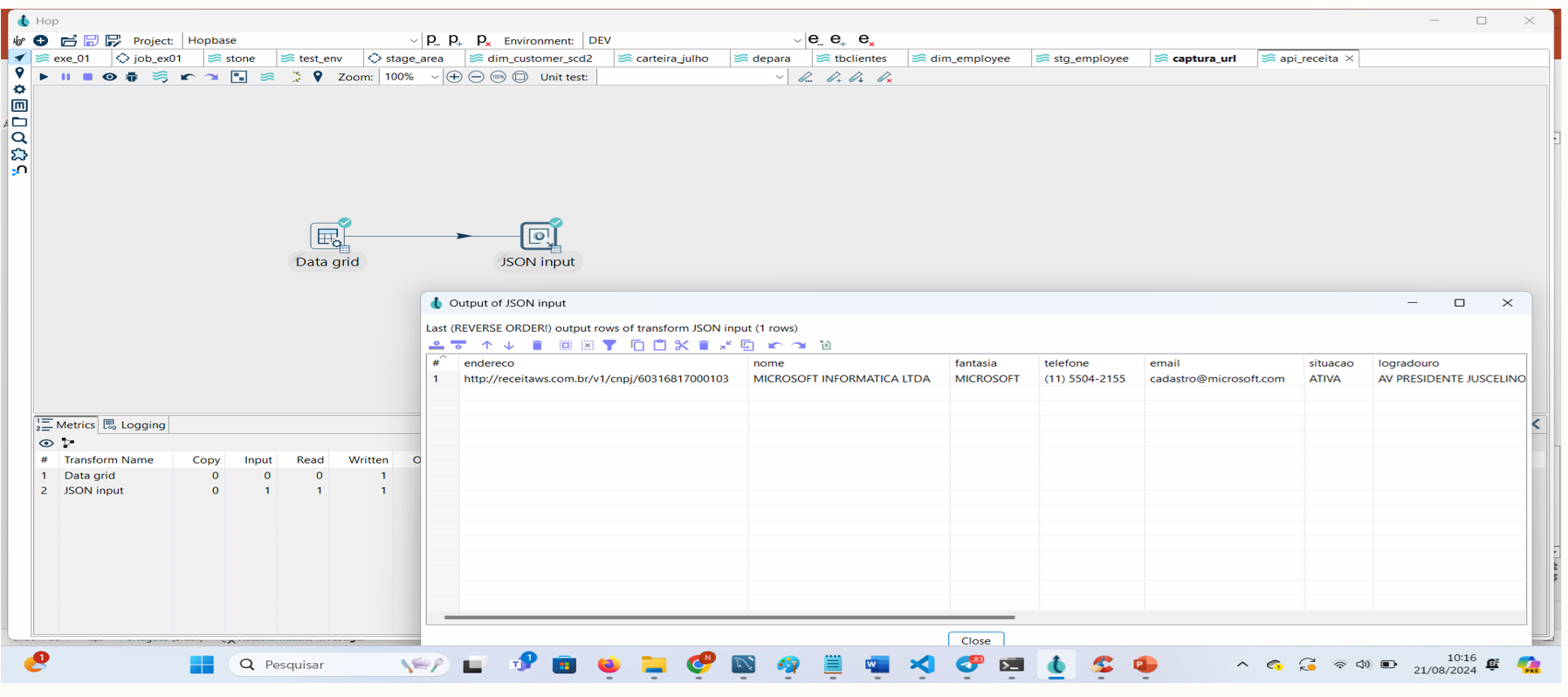
Durante a apresentação, demonstrei como o Apache Hop pode ser utilizado para recuperar dados diretamente da Receita Federal, exemplificando o uso de uma API pública de consulta de CNPJ. A facilidade com que o Apache Hop permite criar pipelines de dados, desde a definição de um simples conjunto de dados estáticos para testes, até a conexão e manipulação de dados JSON vindos de uma API, é algo que pode acelerar significativamente o desenvolvimento de soluções de integração.
A utilização de transformações como o Data Grid, que cria conjuntos de dados estáticos para testes, e o Json Input, que lê e processa dados JSON diretamente da web, exemplifica o quão versátil e eficiente o Apache Hop é para tarefas de ETL. Com poucos cliques, é possível estruturar e transformar dados em informações valiosas para qualquer tipo de análise ou integração.
O Apache Hop se destaca não apenas pela sua flexibilidade, mas também pela facilidade de uso, permitindo que tanto iniciantes quanto profissionais experientes possam configurar pipelines complexos de forma intuitiva. Se você está lidando com grandes volumes de dados ou precisa integrar várias fontes de dados em um fluxo único, o Apache Hop é uma ferramenta que merece sua atenção.
Este é apenas um exemplo do poder e da versatilidade do Apache Hop. Em um cenário onde a qualidade e a integridade dos dados são fundamentais, investir em uma solução robusta como essa pode fazer toda a diferença para o sucesso do seu projeto.
Muito Obrigado.
Nilson Braga
Gostou deste post? Conecte-se comigo no linkedin