
E assim foi o nosso sábado!!!
50 profissionais confiaram no nosso trabalho para aprender como Criar um Data Lake 100% Open Source com Apache Spark!!
Primeiramente nos enche de orgulho ver uma sala tão cheia assim com tantos profissionais incriveis, alguns são nossos alunos desde 2019 quando começamos ensinando ETL com Pentaho e aos novos alunos sejam muito bem-vindos!
Gostaria de destacar a excelência e profundo conhecimento do Wallace Camargo, nosso instrutor neste novo treinamento, que mostrou um domínio absurdo sobre as tecnologias abordada, ainda mais no Spark que foi o foco no 1º dia.
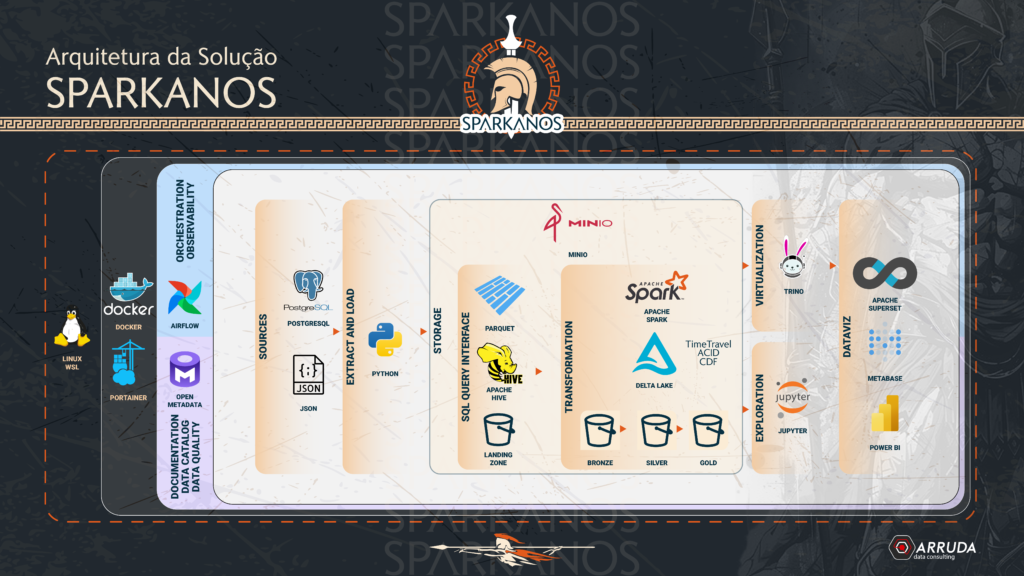
Na parte da manhã, entendemos com o Spark realmente funciona, que é uma aplicação para trabalhar em cluster, ou seja utilizar várias maquinas e não somente uma, entendemos o conceito de manager e works e vimos na prática como o Spark se comporta quando adicionamos e removemos maquinas de forma automática.
Vimos toda as vantagens de utilizar o formato delta:
- AICD.
- Time Travel.
- CDF.
Na parte da tarde foi a vez de criar um Data Lake com Apache Spark, gerando todas as camadas:
- Landing Zone.
- Bronze.
- Silver.
- Gold.
Neste 1º dia utilizamos o Spark para processamento e tratamento dos dados, o MiniO para armazenamento dos dados e o Trino para consulta e manipulação dos dados.
E o mais incrível é que foi tudo 100% Open Source, semana que vem tem mais Spark e também iremos abordar as demais tecnologias da Stack.
Conheça o nosso Treinamento do Sparkanos.
2ª Turma será nos dias 21/09 e 28/09.
Muito Obrigado e uma ótima semana!!
Rafael Arruda