
Apache Spark é um framework open source para computação distribuída, capaz de processar grandes conjuntos de dados.
E o que é computação distribuída?
A computação distribuída é a forma encontrada de conectar diversos computadores e dividir o processamento entre as máquinas, ou seja, é possível dividir uma grande tarefa em pequenas etapas no seu conjunto de máquinas, no final ele junta todos os pedaços e entrega o processamento completo.
Onde ele pode ser encontrado?
Ele pode ser utilizado em plataformas de dados como o Databricks, Microsoft Fabric, Google Colab, localmente ou como serviço gerenciado nas principais clouds.
Quais empresas utilizam o Spark?
O cenário ideal para trabalhar com o Spark é o cenário de Big Data, ou seja, organizações que possuem grandes volumes de dados, tais como: Pic Pay, Bradesco, Ifood, dentre outras.
Fonte: https://www.databricks.com/br/customers
O Spark oferece suporte a várias linguagens de programação, incluindo Scala, Java, Python, SQL e R, tornando-o a uma das ferramentas mais utilizadas para processamento de dados. Podemos ver a seguir exemplos de scripts com a finalidade de fazer apenas um “hello world”:
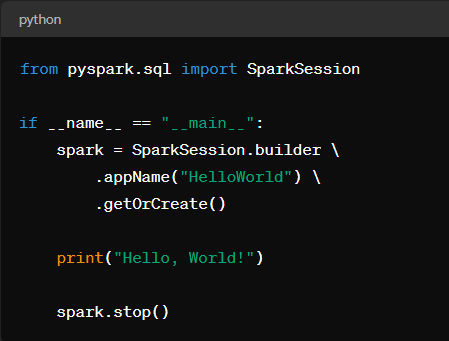
Pyspark – Versão Python para Spark
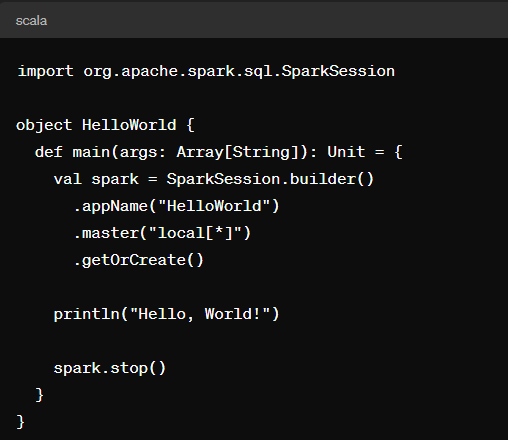
Linguagem Scala – Linguagem nativa do Spark
Apesar de ser suportado em várias linguagens com a possibilidade de transitar entre elas no mesmo mesmo script, as linguagens mais utilizadas no Spark são Python e SQL. No início a adoção dessas linguagens eram baixas por conta da perfomance que era superior em sua linguagem nativa (Scala), mas hoje não há diferença significativa na maioria dos casos e a perfomance é basicamente a mesma em todas as linguagens.
O Spark foi amplamente adotado no cenário de Big Data por conta das suas principais características, tais como:
- Computação em Memória: O Spark permite que os dados sejam armazenados em memória, o que agiliza o acesso e o processamento dos dados. Isso é especialmente útil para operações iterativas e análises interativas que requerem acesso rápido aos dados.
- Suporte a Diversos Workloads: O Spark é projetado para suportar uma ampla variedade de workloads, incluindo processamento em batch, streaming, machine learning, processamento de grafos e consultas interativas. Isso o torna uma ferramenta versátil para diferentes tipos de aplicativos de big data.
- Escalabilidade: O Spark é altamente escalável e pode ser facilmente dimensionado horizontalmente para lidar com grandes volumes de dados. Ele distribui automaticamente o processamento e os dados em um cluster de computadores, permitindo que ele cresça conforme a demanda.
Essas características fazem do Apache Spark uma escolha popular para empresas e organizações que lidam com grandes volumes de dados e buscam uma solução eficiente e escalável para processamento e análise de big data.
Casos de uso
Os scripts podem ser utilizados basicamente em dois formatos, tais como:
1 – Modo submit
2 – Modo de notebook
Obrigado e até o próximo artigo!
Wallace Camargo.