Recentemente comecei a atuar com o Apache Hop, após o curso HopBase, e fiquei curioso para testar as conexões e vi que a do Google BigQuery já vem por padrão no Hop e após alguns testes, consegui fazer a conexão e ainda carregar alguns registros do BigQuery (BQ). Vamos aprender?
Parte 1 – Pegando os dados no Console da GCP
Ao acessar o console da GCP, na primeira página, pegue o ID do Projeto, neste meu teste é “braided-woods-377716“. Agora, navegue até Contas de Serviço.
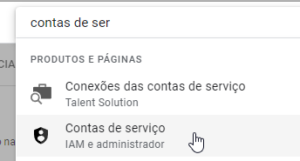
Após acessar esta página, no usuário com permissão de Admin, clique nos três pontinhos na direita, em ações, e marque a opção “Gerenciar Chaves”. Depois, clique em “Criar nova chave”.
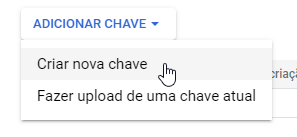
Escolha a opção Json, clique em Criar e salve o arquivo .json que fará o download.
Parte 2 – Instalando o Driver ODBC.
Pesquise sobre “Drivers ODBC e JDBC para BigQuery” no google. A versão atual (março/2023) é a ODBC versão 2.5.2.1004, mas se quiser, clique aqui e tenha acesso direto. Após o download, instale o Driver. Após a instalação, na barra de pesquisa do Windows, procure por “Fontes de Dados ODBC”.
Após abrir a janela, clique em adicionar e localize o “Simba ODBC Driver for Google BigQuery”.
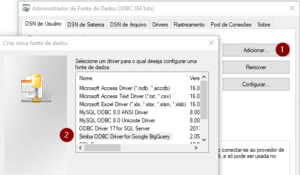
Para configurar, em “Authentication”, escolha a opção “User Authentication” e dê as permissões necessárias.
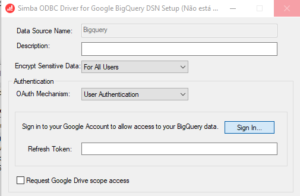
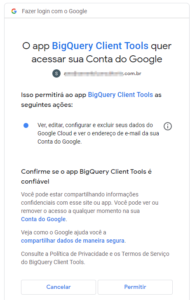
Após permitir, vai aparecer a tela de confirmação e essa é a tela após a autorização:
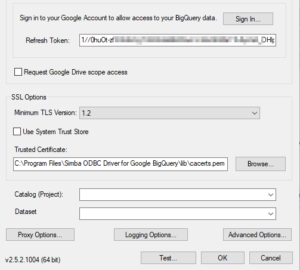
Agora vamos clicar em Test, para ver se está tudo ok. Se tiver chegado até aqui: SUCESSO!!
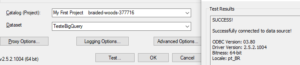
Antes de configurar o Apache, faça o download dos Drivers Jdbc do Google Big Query AQUI, e extraia todos os arquivos “.jar” na pasta Lib > beam, do seu Hop.
Parte 3 – Configurando a conexão no Apache Hop.
Em “Relational Database Connection”, clique em New e escolha o tipo de conexão “Google BigQuery”.
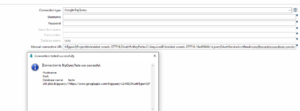
Nesta etapa, vamos colocar apenas a URL, da seguinte forma:
jdbc:bigquery://https://www.googleapis.com/bigquery/v2:443;OAuthType=0;ProjectId=SEU_PROJECT_ID;OAuthPvtKeyPath=DIRETORIO_DO_SEU_JSON;OAuthServiceAcctEmail=SEU_EMAIL_NA_GCP
Ah, Database não pode ficar em branco, então pode colocar qualquer texto
.
Vamos agora consultar os dados no BigQuey, usando o step “Table Input”.
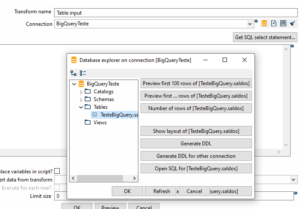
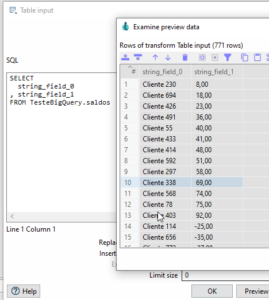
Então, Já temos o acesso ao BigQuery, agora é atuar no pipeline. Neste exemplo, coloquei como saída os dados para um arquivo csv, mas poderia ser outra saída.
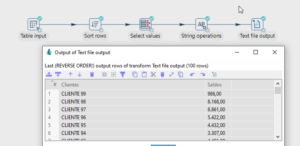
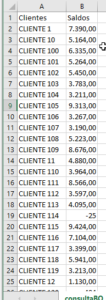
Gostou? Tem alguma contribuição? Manda aqui.
Que tal tentar este processo no Pentaho? Fica a dica: Cria a variável de ambiente (GOOGLE_CLOUD_PROJECT) no Windows e aponta para o id do Projeto.
Quer aprender sobre Hop ou Pentaho? https://arrudaconsulting.com.br/
Thiago Viana