Criando um Processo de Carga Dinâmica com o Pentaho Data Integration
Antes de mais nada Em um projeto de Business Intelligence é muito comum nos depararmos com a necessidade de realizar a migração em massa de tabelas de um banco de dados para outro para termos ganho de tempo no processo de desenvolvimento.
Nesse sentido Digamos que você tenha 50 tabelas num banco de dados SQL Server e estas mesmas tabelas já estejam criadas num banco de dados Postgres ou até mesmo que você queira escolher quais destas tabelas irá carregar os dados para sua área de staging.
Vamos ao desafio…
dentro de um processo normal no Pentaho você precisaria criar uma transformação para cada tabela, porém neste caso temos várias tabelas, sendo assim, como poderíamos criar um processo dinâmico onde pudéssemos realizar esta extração e carga utilizando-se de uma única transformação?
Neste artigo irei te mostrar como fazer um Processo de Carga Dinâmica com o Pentaho !!
Primeiramente, precisamos garantir que todas as tabelas já estejam criadas no banco de dados de destino.
Assim iremos montar a seguinte estrutura:
- Criar um arquivo de parâmetros que contenha as informações do schema e nome das tabelas de origem e destino e uma coluna de FLAG que te permita escolher qual tabela será carregada;
- Desenvolver uma transformação para carregar os dados do arquivo de parâmetros para área de staging;
- Criar um JOB para automatizar o processamento do arquivo;
- Fazer uma transformação para ler os dados do arquivo de parâmetros e guardar o resultado;
- Desenvolver uma transformação que receba os parâmetros e executar dinamicamente a leitura do banco de origem e carregamento da tabela de destino;
- Criar uma JOB que seja executada em forma de looping para cada tabela pré-definida para carga;
Mão na Massa!!!
Para criar o arquivo de parâmetros você pode realizar o comando abaixo, copiar os dados para o Excel e após isso editar seu arquivo para associar as tabelas de origem com as tabelas de destino. Agora Observem o layout do arquivo como deverá ficar!
SELECT
TABLE_CATALOG,
TABLE_SCHEMA,
TABLE_NAME,
FROM INFORMATION_SCHEMA.COLUMNS
O pulo do gato para dinamizar qual tabela carregar está na coluna “CARREGAR_STAGING” onde você poderá marcar SIM para o que deseja processar.
Transformação para carga do arquivo de Parâmetros Carga Staging.
 –
–
Job para processamento do Arquivo de parâmetros
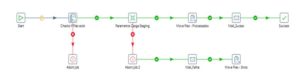
Dessa forma No Job acima estamos inicialmente verificando se o arquivo para processamento esta disponível em seu diretório de origem, ainda assim caso o arquivo esteja na pasta, seguiremos o fluxo, caso contrário o Job será abortado.

Após carregamento do arquivo, o mesmo é movido para uma pasta de arquivos processados e um e-mail de sucesso será enviado.
Assim Caso tenhamos erro no processamento do arquivo, o mesmo será movido para uma pasta de erro e um e-mail de falha será enviado.
Agora vamos montar o processo de carga!!
Com os dados do arquivo de parâmetros já atualizados em nossa staging iremos criar a seguinte transformação:
Parâmetros Staging
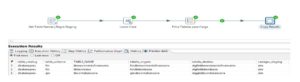
Dessa forma No primeiro step lemos a nossa staging para obter os dados do arquivo de parâmetros, com o string operations, colocamos todos os campos com letra minúscula para que fiquem com o mesmo nome das tabelas de origem e destino.
Além disso O step filter rows se encarregará de filtrar o que esteja classificado como SIM, dessa forma carregamos dinamicamente apenas as tabelas que escolhemos, por fim, utilizamos o step copy rows para que possamos utilizar estas informações em outra transformação em tempo de execução.
Nesse sentido agora iremos criar uma transformação para fazer o “get” deste resultado gerado na transformação acima e por fim salvar isso numa variável.
Get Tabelas Carga

Configuração do step Get rows from result.

Configuração do step Set Variables
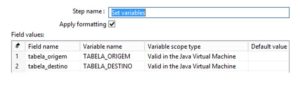
Ou seja Agora que temos as tabelas de origem e destino já definidas e armazenadas em variáveis precisamos usa-las para manipular nosso step de table Input e table output.
Vamos lá!!
Nesse sentido Vamos criar a transformação conforme modelo abaixo:
Carga Dinâmica Staging

Configuração do Table Input:
Primeiramente Coloque seu comando select * from atribuindo a variável da tabela de origem e marque a opção replace variables in script
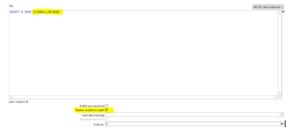
Configuração do Table Output:
Agora Digite o nome do seu schema de destino e no campo target table indique a variável da sua tabela de destino.

Dessa forma já temos as tabelas em processo dinâmico de atualização, mas…
Como devemos criar o JOB para orquestrar este processo?
Vamos lá, mão na massa!!!
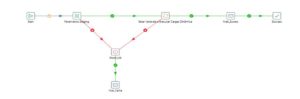
Antes de mais nada o Nosso JOB Principal terá a seguinte estrutura:
A primeira transformação irá executar a Parâmetros Staging, e em seguida, executará o JOB Setar Variáveis e Executar Carga Dinâmica.
Agora o pulo do gato para esta execução dinâmica está na configuração do JOB Setar Variáveis e Executar Carga Dinâmica, ele precisa estar marcado para executar a cada linha. Observe imagem abaixo:
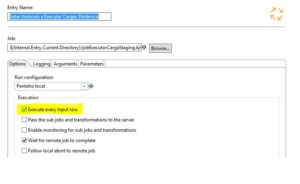
Job Setar Variáveis e Executar Carga Dinâmica:
– Get Tabelas Origem e Destino: Executa a transformação Get Tabelas Carga.
– Carga Dinâmica Staging: Executa a transformação Carga Dinâmica Staging.

Dessa Forma Nosso Job de carga dinâmica deverá ficar da seguinte forma:
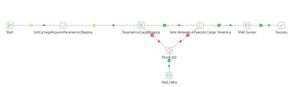
Em suma, É dessa forma que conseguiremos Criar um Processo de Carga Dinâmica com o Pentaho de diversas tabelas em uma única transformação!!
Material de Aprofundamento:
Se Você quiser Aprender Pentaho de verdade do Zero Até o avançado, como construir um DW, aprender a automatizar seu processo de BI, ETL e muito mais, então Confira Nosso Curso Completo de Pentaho. CLICANDO AQUI
Você ainda ganha acesso a nossa comunidade de alunos Pentarruda onde ajudamos uns aos outros compartilhando muita informação e resolvendo dúvidas relacionado a Engenharia de Dados e Business Intelligence!
Excelente postagem Kleber, bastante conteúdo.
Conteúdo sensacional!
Valeu Ronyel, que bom que gostou.
You can certainly see your skills in the article you write.
The world hopes for more passionate writers such as you who
aren’t afraid to mention how they believe. All the time follow your heart.
Good post. I learn something new and challenging on blogs I stumbleupon on a daily basis. Its always useful to read content from other writers and use a little something from their sites.
Excelente postagem! Tudo muito bem detalhado.
Permita-me perguntar como você trata com arquivos grandes.
No meu exemplo, tenho extrações de tabelas em MySQL onde geram transformações para planilhas Google com mais de 25MB.
Há algum tratamento ou configurações específicas a serem feitas no Pentaho?
Mais uma vez, parabéns pelo conteúdo!
Esse processo também seria possível utilizando arquivos excel para carregar as tabelas?
É possível sim!!!!
A fonte de dados pode mudar mas o conceito é o mesmo!!